Prioritizing
The more frequently a morph occurs in a language, the more useful it is to learn. This is the fundamental principle behind AnkiMorphs–learn a language in the order that will be the most useful.
AnkiMorphs is a general purpose language learning tool, therefore, it has to be told which morphs occur most often. You
can do this in two ways, either have AnkiMorphs calculate the morph frequencies found in your
cards (Collection frequency), or you can specify a custom .csv file that contains that information.
Any .csv file located in the folder [anki profile folder]/priority-files/ is
available for selection in note filters: morph priority.
But before we outline the custom priority files, we have to discuss morph lemmas and inflections.
Lemmas or Inflections?
There are scenarios where you might not want to give each individual inflection a separate priority:
-
Chinese technically does not have inflections, so any inflection data is artificial and leads to a wasteful use of resources.
-
Korean has an extreme number of inflections, leading to an explosion of priorities, which creates disproportionate penalties.
-
You might feel that you have a good enough grasp of the grammar of inflections, making it unnecessary to prioritize one over another.
If you never want to give separate priorities to inflections then you should choose a lemma only priority file. If you do care about inflection priorities, or if you might want to switch to lemma priorities on the fly, then choose an inflection priority file.
Custom Priority Files
You can use the Priority File Generator or the Study Plan Generator to create your own custom priority file, or you can download some pre-made ones at the bottom of this page.
Note:
- The
Occurrencescolumn is optional- Any lines after 1 million will be ignored by AnkiMorphs
Custom Lemma Priority Files
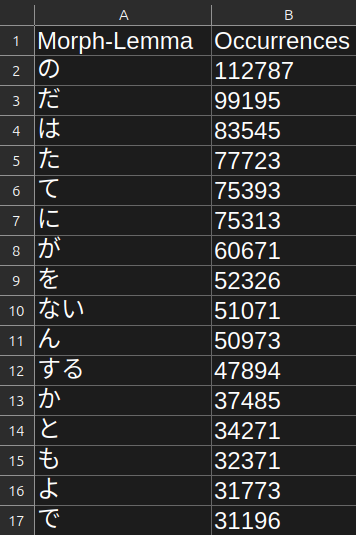
The lemma only priority files follows this format:
- The first row contains column headers.
- The second row and down contain morph lemmas in descending order of frequency.
Custom Inflection Priority Files
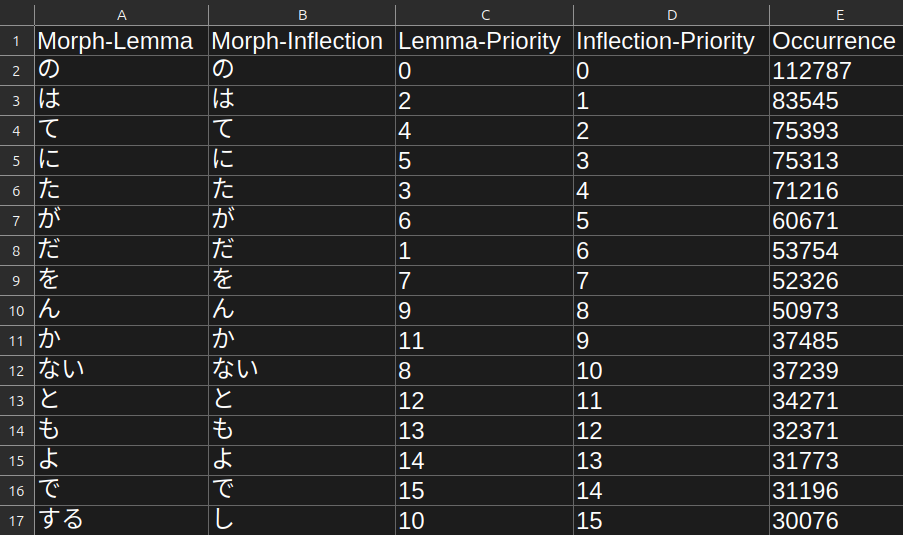
The inflection priority files follows this format:
- The first row contains column headers.
- The second row and down contain morphs in descending order of inflection frequency.
- The first column contains morph-lemmas, the second column contains morph-inflections (this is done to prevent morph collisions).
- The third column contains lemma priorities, the fourth column contains inflection priorities (this is done to so you can switch morph evaluation on the fly).
Morph Collision
Inflected morphs can be identical even if they are derived from different lemmas (base), e.g.:
Lemma : Inflection
有る ある
或る ある
To prevent misinterpretation of the inflected morphs, we also store the lemmas.
Downloadable Priority Files
Unless stated otherwise, these are inflection priority files, generated using a 90% comprehension cutoff.
Cantonese
Note: This is a lemma only priority file that was not generated using AnkiMorphs, so it might not work very well (or at all).
- zhh-freq.csv
- Source:
existingwordcount.csvfound on words.hk - analysis
Catalan
- ca-news-priority.csv
- Source:
cat_news_2022_300K-sentences.txtfound on wortschatz - catalan corpora- Morphemizer:
spaCy: ca-core-news-sm
Chinese
Note: this is a lemma only priority file.
- zh-news-lemma-priority.csv
- Source:
zho_news_2020_300K-sentences.txtfound on wortschatz - chinese corpora- Morphemizer:
AnkiMorphs: Chinese
Croatian
- hr-news-priority.csv
- Source:
hrv_news_2020_300K-sentences.txtfound on wortschatz - croatian corpora- Morphemizer:
spaCy: hr-core-news-sm
Danish
- da-news-priority.csv
- Source:
dan_news_2022_300K-sentences.txtfound on wortschatz - danish corpora- Morphemizer:
spaCy: da-core-news-sm
Dutch
- nl-news-priority.csv
- Source:
nld_news_2022_300K-sentences.txtfound on wortschatz - dutch corpora- Morphemizer:
spaCy: nl-core-news-sm
English
- en-wiki-priority.csv
- Source:
eng_wikipedia_2016_300K-sentences.txtfound on wortschatz - english corpora- Morphemizer:
spaCy: en-core-web-sm
Finnish
- fi-news-priority.csv
- Source:
fin_news_2022_300K-sentences.txtfound on wortschatz - finnish corpora- Morphemizer:
spaCy: fi-core-news-sm
French
- fr-news-priority.csv
- Source:
fra_news_2022_300K-sentences.txtfound on wortschatz - french corpora- Morphemizer:
spaCy: fr-core-news-sm
German
- de-news-priority.csv
- Source:
deu_news_2022_300K-sentences.txtfound on wortschatz - german corpora- Morphemizer:
spaCy: de-core-news-md
Greek (Modern)
- el-news-priority.csv
- Source:
ell_news_2022_300K-sentences.txtfound on wortschatz - modern greek corpora- Morphemizer:
spaCy: el-core-news-sm
Italian
- it-news-priority.csv
- Source:
ita_news_2022_300K-sentences.txtfound on wortschatz - italian corpora- Morphemizer:
spaCy: it-core-news-sm
Japanese
- ja-news-priority.csv
- Source:
jpn_news_2011_300K-sentences.txtfound on wortschatz - japanese corpora- Morphemizer:
AnkiMorphs: Japanese- ja-anime-priority.csv
- Source: NanakoRaws
- Morphemizer:
AnkiMorphs: Japanese
Korean
Note: this is a lemma only priority file.
- ko-news-lemma-priority.csv
- Source:
kor_news_2022_300K-sentences.txtfound on wortschatz - korean corpora- Morphemizer:
spaCy: ko-core-news-sm
Lithuanian
- lt-news-priority.csv
- Source:
lit_news_2020_300K-sentences.txtfound on wortschatz - lithuanian corpora- Morphemizer:
spaCy: lt-core-news-sm
Macedonian
- mk-news-priority.csv
- Source:
mkd_newscrawl_2011_300K-sentences.txtfound on wortschatz - macedonian corpora- Morphemizer:
spaCy: mk-core-news-sm
Norwegian (Bokmål)
- nb-news-priority.csv
- Source:
nob_news_2013_300K-sentences.txtfound on wortschatz - norwegian corpora- Morphemizer:
spaCy: nb-core-news-sm
Polish
- pl-news-priority.csv
- Source:
pol_news_2022_300K-sentences.txtfound on wortschatz - polish corpora- Morphemizer:
spaCy: pl-core-news-sm
Portuguese
- pt-news-priority.csv
- Source:
por_news_2022_300K-sentences.txtfound on wortschatz - portuguese corpora- Morphemizer:
spaCy: pt-core-news-sm
Romanian
- ro-news-priority.csv
- Source:
ron_news_2022_300K-sentences.txtfound on wortschatz - romanian corpora- Morphemizer:
spaCy: ro-core-news-sm
Russian
- ru-web-priority.csv
- Source:
rus-ru_web-public_2019_300K-sentences.txtfound on wortschatz - russian corpora- Morphemizer:
spaCy: ru-core-news-sm
Slovenian
- sl-news-priority.csv
- Source:
slv_news_2020_300K-sentences.txtfound on wortschatz - slovenian corpora- Morphemizer:
spaCy: sl-core-news-sm
Spanish
- es-news-priority.csv
- Source:
spa_news_2022_300K-sentences.txtfound on wortschatz - spanish corpora- Morphemizer:
spaCy: es-core-news-sm
Swedish
- sv-news-priority.csv
- Source:
swe_news_2022_300K-sentences.txtfound on wortschatz - swedish corpora- Morphemizer:
spaCy: sv-core-news-sm
Ukrainian
- uk-news-priority.csv
- Source:
ukr_news_2022_300K-sentences.txtfound on wortschatz - ukrainian corpora- Morphemizer:
spaCy: uk-core-news-sm