amazing work on the original version of the user guide!
Introduction
AnkiMorphs is an Anki add-on that can rearrange your cards based on how well you know the words on them and how important the words are to learn. This ensures that your cards are arranged in the best order for optimal language learning.
AnkiMorphs goes through the text on the cards you specify, and parses the text into morphs (basically words). It assumes you already know all the morphs contained within the cards you’ve learned. In this way, it creates a database of your current knowledge and uses that database to analyze how many unknown morphs are contained within each of your new cards.
It then reorders your new cards based on their score so that you see the easiest cards (i.e., the cards with the fewest number of unknown morphs) first. AnkiMorphs only reorders your new cards; it doesn’t touch the scheduling of cards you’ve already learned. You can tell AnkiMorphs to re-analyze and reorder your cards as often as you like. This allows you to always learn new cards in a 1T fashion.
This guide is an attempt to explain how AnkiMorphs functions as simply as possible. Feel free to skip straight to Installation, Setup, or Usage, and refer back to the Glossary whenever clarification is needed.
Glossary
1T Sentence
Abbreviation for “one-target sentence”. A sentence that contains one unknown word or grammar structure. The unknown word or structure is referred to as the “target word” or “target structure”.
Learning through 1T sentences can be thought of as “picking low-hanging fruit”. It makes the target word/structure easy to understand and retain. As you continue to learn, sentences that were previously one-target will become zero-target, and sentences that were previously multi-target will become one-target. In this way, one-target sentences can take you all the way to fluency.
Learn about the “Input Hypothesis”
MT Sentence
Abbreviation for “multi-target sentence”. A sentence that contains more than one unknown word or grammar structure.
Morph
A morph is a basic unit of meaning in language. It’s short for the word “morpheme,” which is the smallest grammatical unit of speech. A morpheme can be a whole word, like “book” or “run,” or a part of a word, like prefixes (re- in “rewrite”) or suffixes (-ed in “walked”).
Lemma
A lemma is the base form of a word. It’s the version you would typically find in a dictionary. For example:
- The lemma for “running,” “ran,” and “runs” is “run.”
- The lemma for “better” and “best” is “good.”
Inflection
An inflection is a variation of the base form that shows different grammatical features such as tense, case, voice, aspect, person, number, gender, mood, or comparison. For example:
- “run” (base form) can change to “running,” “ran,” or “runs” to show different tenses.
- “good” (base form) can change to “better” or “best” to show comparison.
Morphs as tuples
In many language learning systems, morphs are considered as tuples containing two values: a lemma (base form) and an inflection. Here’s a simple example table showing different morphs for the verb “to break”:
| Lemma | Inflection |
|---|---|
| break | break |
| break | breaks |
| break | breaking |
| break | broke |
| break | broken |
Understanding and breaking down morphs into lemmas and inflections can be incredibly useful for language learning. It allows you to focus on the fundamental building blocks of words, making it easier to grasp new vocabulary and grammatical structures. This approach can help in creating more effective and personalized study methods, potentially leading to faster and more efficient learning.
New cards
A card is considered “new” by Anki if it hasn’t been studied yet, meaning you have never answered the card with “Again”, “Hard”, “Good”, or “Easy”.
You can tell if a card is in the ‘new’ state when its due value looks like this: New #....
After reviewing a card, you can change its state back to “new” by using the reset option.
Reviewed cards
Once a card has been studied, i.e. answered with either “Again”, “Hard”, “Good”, or “Easy”, it will move from the “new” state into the “review” state.
Unknown Morphs
A morph is classified as unknown if it does not appear on any review cards and is not stored in the known morphs folder.
Known Morphs
A morph is classified as known if it is on a review card with a learning interval of at least the known morph interval setting, or if it is stored in the known morphs folder.
Fresh Morphs
Fresh morphs are morphs that appear only on cards whose learning intervals are below the Known Morphs Interval threshold. Once a morph appears on a card whose interval meets or exceeds that threshold, it is no longer considered fresh.
- New cards have a learning interval of 0 days.
- Learning cards have a learning interval of 1 day.
- Review cards have learning intervals that vary based on scheduling and review history.
Profile folder
For AnkiMorphs to work, it needs to use some dedicated files and folders, namely:
ankimorphs.dbnames.txtpriority-files/known-morphs/
Those can be found in the Anki profile folder. The path to the Anki profile folder depends on your operating system:
- Windows:
C:\Users\[user]\AppData\Roaming\Anki2\[profile_name] - Mac:
/Users/[user]/Library/Application Support/Anki2/[profile_name] - Linux:
/home/[user]/.local/share/Anki2/[profile_name]
sub2srs
You can get automatically generated Anki cards from tv-shows or movies by using a tool called sub2srs. Generating decks with sub2srs is pretty technical, so I recommend finding sub2srs decks other people have already made.
You can download many different anime sub2srs decks from this site.
Installation
You can download the latest version of AnkiMorphs from ankiweb. You can find previous versions on github releases.
AnkiMorphs parses text into morphs by using external morphemizers, and different languages will require different morphemizers. Below are the currently supported morphemizers:
Japanese morphemizers
Japanese has two available morphemizers:
MeCab morphemizer (recommended)
This can be added by installing the ankimorphs-japanese-mecab companion add-on (installation code:1974309724). Once this add-on has been installed and Anki has been restarted, the morphemizer will show up as the optionAnkiMorphs: Japaneseinstall spaCy with Japanese models
Chinese morphemizers
Chinese has two available morphemizers:
Jieba morphemizer (recommended)
This can be added by installing the ankimorphs-chinese-jieba companion add-on (installation code:1857311956). Once this add-on has been installed and Anki has been restarted, the morphemizer will show up as the optionAnkiMorphs: Chineseinstall spaCy with Chinese models
Arabic morphemizers (Linux/macOS)
Arabic support is provided via CAMeL Tools (NYU Abu Dhabi), which includes dedicated morphological databases for:
- Modern Standard Arabic (
calima-msa-r13)- Egyptian Arabic (
calima-egy-r13)- Gulf Arabic (
calima-glf-01)CAMeL Tools provides proper lemmatization — so
الكتابandكتابare correctly recognized as the same lemma.See the full installation guide for details.
Morphemizers for other languages
For other languages you can install spaCy, which currently supports:
Catalan, Chinese, Croatian, Danish, Dutch, English, Finnish, French, German, Greek (Modern), Italian, Japanese, Korean, Lithuanian, Macedonian, Norwegian (Bokmål), Polish, Portuguese, Romanian, Russian, Slovenian, Spanish, Swedish, Ukrainian.
After the installation is complete, some setup is required to get AnkiMorphs to work. After that you can run Recalc and you will be good to go!
Here is an overview of the changes that are made to Anki after installing AnkiMorphs.
Installing spaCy
From the Anki Tools menu, navigate to AnkiMorphs -> spaCy Manager

which will take you to the spaCy manager window:
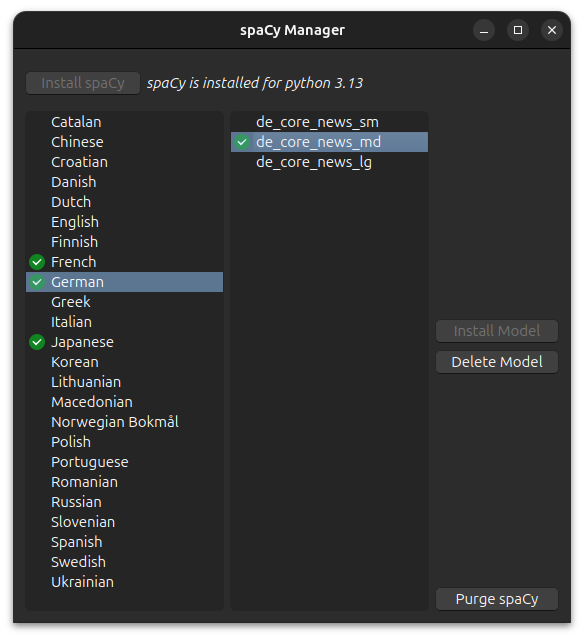
-
Installing spaCy:
Note: spaCy is specific to the Python version it was installed for; a version built for Python 3.9 will not work with Python 3.10, and vice versa.
When you click install, spaCy will automatically be downloaded and installed into a dedicated folder (virtual environment), which can be found here:
- Windows:
%APPDATA%\Anki2\addons21\spacy-venv-python-<version> - macOS:
~/Library/Application Support/Anki2/addons21/spacy-venv-python-<version> - Linux:
~/.local/share/Anki2/addons21/spacy-venv-python-<version>
After the installation is complete you have to restart Anki before you can install any models.
- Windows:
-
Install Model:
Note: The models are stored in the virtual environment folder.
There are usually three different types of models (morphemizers) to choose from for each language, each with their distinct suffixes:
- sm (small model): ~10–50 MB
- md (medium model): ~50–150 MB
- lg (large model): ~500 MB+
Larger models are slower, but they might produce better results.
-
Delete Model:
Deletes the model from the virtual environment folder. -
Purge spaCy
Removes the entire virtual environment folder, removing both spaCy and its models.
Installing CAMeL Tools (Linux/macOS)
CAMeL Tools is an Arabic NLP library developed by the CAMeL Lab at NYU Abu Dhabi. It provides proper
morphological analysis for Arabic, recognizing that الكتاب and كتاب share the same lemma — something
the Simple Space Splitter cannot do.
From the Anki Tools menu, navigate to AnkiMorphs → CAMeL Tools Manager.
Step 1: Install CAMeL Tools
System requirements (per the CAMeL Tools installation docs):
- Python 3.11–3.14, 64-bit (Anki’s bundled Python must meet this requirement)
- The Rust compiler must be installed before clicking Install
cmakeandboostmust be installed before clicking Install
- macOS:
brew install cmake boost- Ubuntu/Debian:
sudo apt-get install cmake libboost-all-dev
Note: CAMeL Tools downloads and installs ~5.5 GB of dependencies.
Click Install CAMeL Tools. This downloads and installs CAMeL Tools into a dedicated virtual environment inside your Anki add-ons folder. After installation completes, restart Anki.
Step 2: Install a Database
After restarting Anki, open the CAMeL Tools Manager again. The databases list shows the available Arabic morphology databases:
| Database | Dialect | License | Download size |
|---|---|---|---|
Modern Standard Arabic (calima-msa-r13) | MSA | GPL v2 | 40.5 MB |
Egyptian Arabic (calima-egy-r13) | Egyptian | GPL v2 | 67.3 MB |
Gulf Arabic (calima-glf-01) | Gulf | CC BY 4.0 | 8.0 MB |
After installation completes, restart Anki again. The morphemizer will now appear in the
Settings → Note Filter dropdown as e.g. CAMeL Tools: Egyptian Arabic.
Purging CAMeL Tools
Click Purge CAMeL Tools to remove the entire CAMeL Tools virtual environment and databases.
License Note
The MSA and Egyptian Arabic databases (calima-msa-r13, calima-egy-r13) are derived from the ALMOR
database distributed with MADAMIRA (Columbia University) and are licensed under GPL v2. The Gulf Arabic
database (calima-glf-01) is licensed under CC BY 4.0. The CAMeL Tools Python library itself is MIT
licensed. Users download the databases directly from the CAMeL Tools data repository.
Changes To Anki
After installing AnkiMorphs you will find that some changes have been made to Anki.
Toolbar

The toolbar now has three new items:
- Recalc
L, which stands forKnown Morph LemmasI, which stands forKnown Morph Inflections
English examples of L and I
Each column in the table contains a morph lemma, and every row in a column contains a different inflection of that lemma.
Knowing the morph in the highlighted cell below would give you L: 1 and I: 1
go break read walk went broke read walked going breaking reading walking gone broken read walked Knowing the morphs in the highlighted cells below would give you L: 1 and I: 2
go break read walk went broke read walked going breaking reading walking gone broken read walked Knowing the morphs in the highlighted cells below would give you L: 2 and I: 3
go break read walk went broke read walked going breaking reading walking gone broken read walked
Japanese examples of L and I
Each column in the table contains a morph lemma, and every row in a column contains a different inflection of that lemma.
Knowing the morph in the highlighted cell below would give you L: 1 and I: 1
ない 物 奴 出 ねぇ もの やつ 出る ね もん ヤツ 出よう Knowing the morphs in the highlighted cells below would give you L: 1 and I: 2
ない 物 奴 出 ねぇ もの やつ 出る ね もん ヤツ 出よう Knowing the morphs in the highlighted cells below would give you L: 2 and I: 3
ない 物 奴 出 ねぇ もの やつ 出る ね もん ヤツ 出よう
The L and I numbers are updated after every Recalc.
Note: Chinese and other languages that don’t have inflections will result in
LandIhaving equal numbers.
Browse
AnkiMorphs adds new options in the Browse window
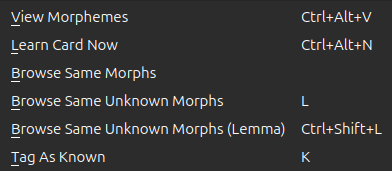
These options can be accessed either from the context menu when right-clicking cards, or from the AnkiMorphs menu at
the top of the Browse window:

These features are explained here.
Tools Menu
An AnkiMorphs submenu is added to the Anki Tools menu:
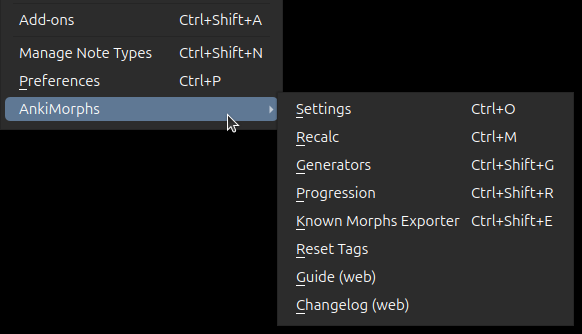
You can find info about the options here:
Setup
The setup guide is separated into the following sections:
- Decks: which deck-options to use and other miscellaneous deck tips
- Settings: details about the AnkiMorphs settings options
- Prioritizing: how to give priority to morphs
- Names: how to specify names to ignore
- Setting Known Morphs: how to import known morphs
- Highlighting: how to highlight text on your cards
Decks
The more cards you have with unique morph combinations, the more likely AnkiMorphs is to find the ideal next learning card for you. Large decks like those generated by sub2srs are therefore well-suited for AnkiMorphs. The drawbacks of large decks are that they require more disk space and the first sync might take a while, so find a size that works best for you.
In this guide I will be using this Japanese to English deck with 37K sub2srs cards.
If your deck has sub-decks like mine does then you also need to change one deck-options setting to get it working properly.
First Sync
The first time you sync a deck from/to a device, the media files are downloaded/uploaded which can take a long time depending on how many files there are. Note that sub2srs cards usually have two media files (screenshot image and sentence audio), which results in more files being synced than there are cards.
Errors can occur during the sync process, but the progress is usually saved, and you just have to click the sync button again.
Every subsequent sync should be lightning fast, even if AnkiMorphs makes changed to all your cards, it will usually only take a couple of seconds to sync with a normal internet connection because no media files were changed.
Deck-options
If your deck has sub-decks like mine does, then you need to configure the deck option in Anki to gather new cards from all the sub-decks, otherwise Anki only pulls new cards from one sub-deck at a time until that deck is empty. To fix this do the following:
- Go to the deck options of the deck that has sub-decks
- Go to
Display Order - Set
New card gather ordertoAscending position
Using Existing Decks
If you have already studied cards and are comfortable with their content, you can configure AnkiMorphs to read and/or modify them as shown in the note filter section. This can significantly speed up your progress, as the add-on will identify the morphs you already know, letting you skip redundant reviews and focus on new material.
Adding a lot of semi-known vocabulary at the same time can be overwhelming, so it’s a good idea to err on the side of caution and only add material that you know you are comfortable with. For example, if you’ve been studying a vocabulary deck, it’s probably better to have AnkiMorphs read the word field, and not the example sentence field.
If you decided to create a note filter with your already studied cards, but realize you’ve bitten off more than you can chew, you can simply delete the note filter or uncheck the “read” option and AnkiMorphs will then stop treating those morphs as known.
Settings
To display the settings dialog either use Ctrl+Shift+S or go to Tools -> AnkiMorphs -> Settings
The settings are separated into the following sections:
- General: miscellaneous settings
- Note Filter: set which cards you want AnkiMorphs to analyze and sort
- Extra Fields: have AnkiMorphs add extra information to your cards
- Tags: rename the tags AnkiMorphs uses
- Preprocess: adjust the text AnkiMorphs analyzes
- Card Handling: adjust how AnkiMorphs handles cards
- Algorithm: adjust the scoring algorithm
- Shortcuts: adjust keyboard shortcuts
General
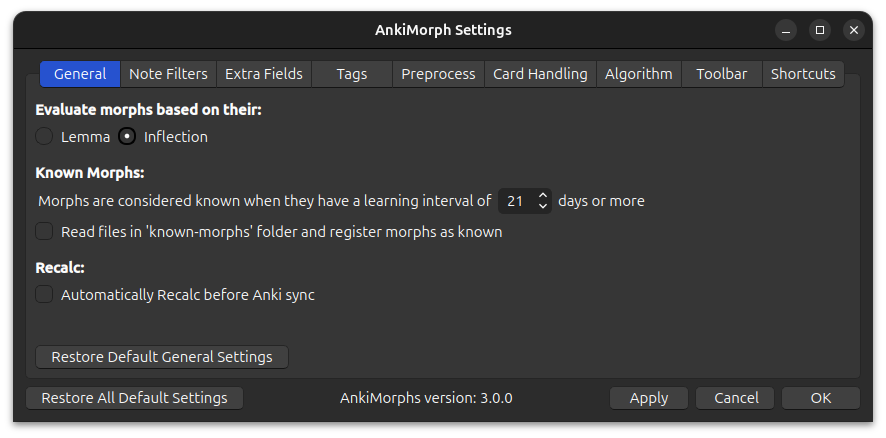
Morph Evaluation
- Evaluate morphs based on their lemma or inflection:
This impacts the two things:- scoring algorithm: use the morph priority associated with the inflection or the lemma.
- skipping: skip morphs based on their lemma or inflection.
Known Morphs
-
Morphs are considered known when […]:
This variable is used when text is highlighted, and it determines the L and I numbers. -
Use FSRS card stability instead of card interval for known threshold:
Note: make sure you have FSRS enabled when using this option
By default, AnkiMorphs determines whether a morph is “known” based on the card’s review interval (how many days until you next see the card). With this option enabled, it instead uses the FSRS stability value: how many days it will take for the card to go from 100% retrievability to 90% retrievability.
This is very useful if you have decks or presets with different desired retention (DR) thresholds. For example, two cards may be “known” equally well, but differences in DR and individualized FSRS parameters can cause significant card interval discrepancies:
Card Deck DR Interval Stability Card1 95% 10d 30d Card2 80% 50d 30d This interval discrepancy can cause misleading “known” values for morphs. Using stability avoids this problem, since it reflects actual memory strength independent of DR.
-
Read files in ‘known-morphs’ folder and register morphs as known:
Import known morphs from theknown-morphsfolder. Read more in Settings Known Morphs.
On Sync
- Automatically Recalc before Anki sync:
Recalc automatically runs before Anki syncs your card collection.Note: If you use the FSRS4Anki Helper add-on with an
Auto [...] after sync-option enabled, then this can cause a bug where sync and recalc occurs simultaneously.
Toolbar
-
Hide toolbar items::
If you want to declutter the toolbar you can choose to hide any of the toolbar items provided by the addon. -
Toolbar counter (‘L’ and ‘I’) shows:
-
Seen morphs:
Shows all morphs that have been reviewed at least once. This can be more motivating than only seeing known morphs since it goes up every time you study new cards, but it can also give you a false sense of confidence. -
Known morphs:
Only show known morphs, which is determined byMorphs are considered known when [...]option in the general setting.
-
Note Filter
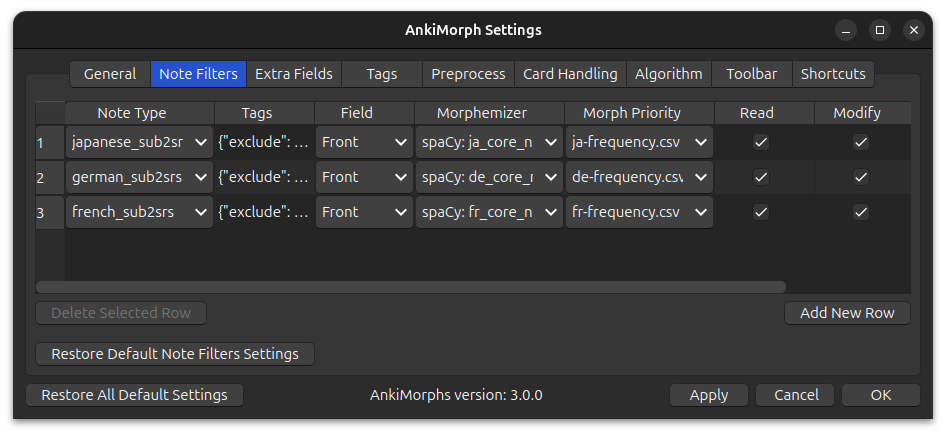
AnkiMorphs only analyzes and sorts cards that match at least one note filter; if you don’t specify any note filters, then AnkiMorphs won’t do anything, so this is a necessary step. This can seem overly complicated and overwhelming, but hopefully things will make sense after reading to the end of this page. This is really the heart of the add-on, and it has some powerful options (notably tags), so having a good understanding of note filters work might significantly improve how much you benefit from AnkiMorphs.
Each note filter contains:
- Note Type
- Tags (optional)
- Field
- Morphemizer
- Morph Priority
- Read & Modify (optional)
Note Type
To find a card’s note type do the following:
- Go to Browse
- Find a card you want AnkiMorphs to analyze and sort
- Right-click the card
- Click Info
- See
Note Type
All the cards in my Japanese Sentences deck (and sub-decks) have the same note type, but that might not be the case
for your decks.
Another thing you can do is look through the Note Types in the left sidebar and until you find the cards you are
after.
Tags
You can further filter AnkiMorphs to only work on cards with a certain note type and with/without specific tag(s).
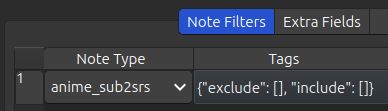
Let’s use an example of having a note type: anime_sub2srs. The card break-down of the note type is the following:
- Total cards: 20K
- Cards with the tag
demon-slayer: 6k - Cards with the tag
movie: 3k - Cards with the tag
fight-scene: 2k - Cards that have both
demon-slayerandmovietags: 1k
If you want all the 20K cards of note type anime_sub2srs then leave the tags empty (default):
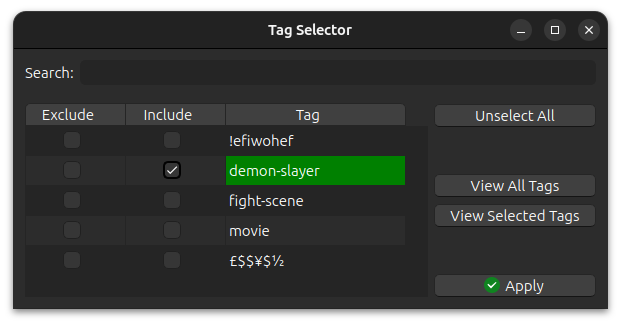
If you want the 6K cards with the demon-slayer tag:
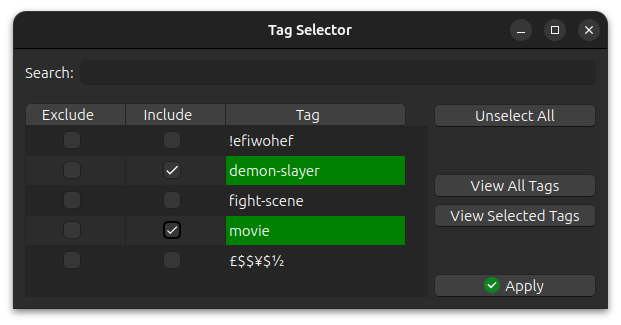
If you want the 1k cards that have both demon-slayer and movie tags, i.e. the intersection:
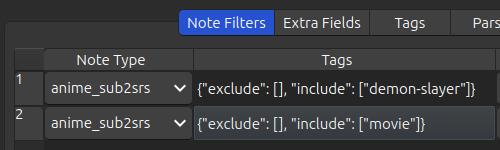
If you want the 8K cards that have either demon-slayer or movie tags, i.e. the union, then you have to create
two note-filters like this:
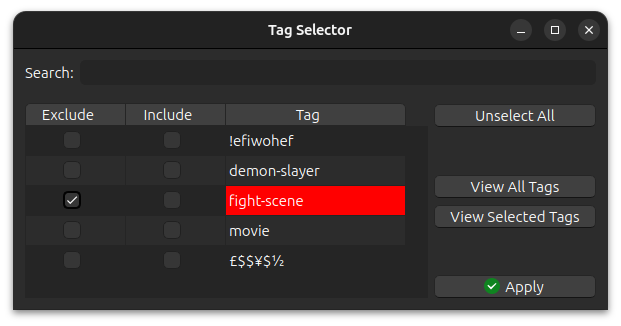
If you want the 18K cards that don’t have the fight-scene tag:
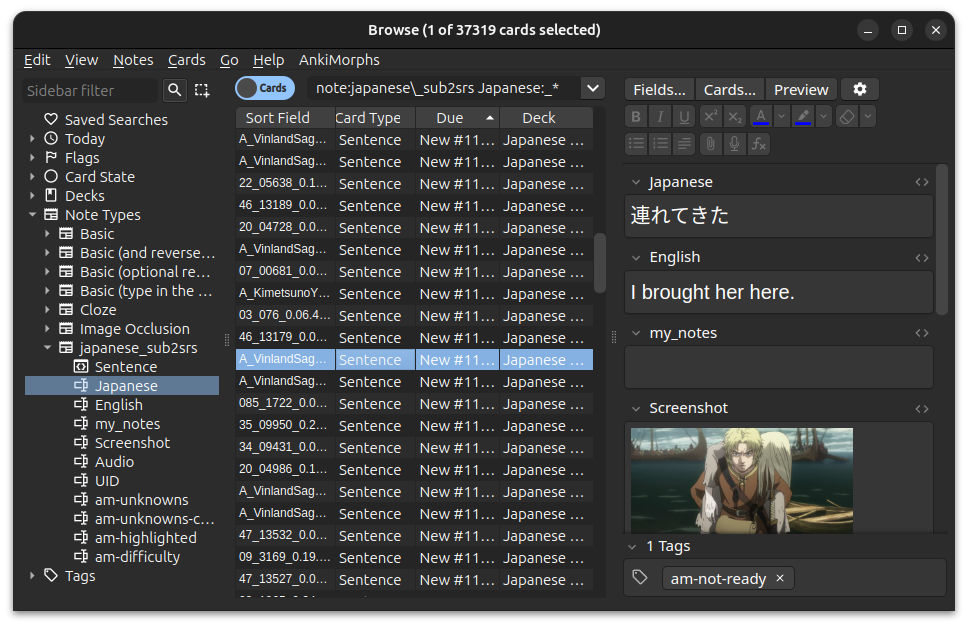
Field
This is the field on the card AnkiMorphs reads and analyzes, which is then used to sort the card.
- Go to Browse
- Find the note type in the left sidebar
- Find the field you care about
In my case the field I’m interested in is Japanese
Note: Fields with complete sentences are preferable over fields that only have isolated words. The more context the morphemizers are given, the less likely they are to produce false positives.
Morphemizer
This is the tool AnkiMorphs uses to split text into morphs. See the installation section for how to add morphemizers.
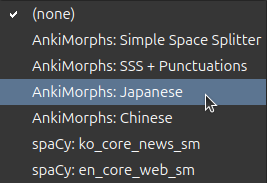
Simple Space Splitter
As the name suggests, this morphemizer just splits words based on whitespace and does not perform any linguistic analysis, meaning they won’t provide accurate lemmas. You should only use this if no other morphemizers are available for your particular target language.
If you use this morphemizer, punctuation and other unwanted characters will likely be included in the morphs. To fix this, you can specify custom characters to ignore in the preprocess settings.
Morph Priority
The calculated score of the card, and as a result, the sorting of the card, depends on
the priority you give the morphs. You can either set the priorities to be Collection frequency (how often the
morphs occur in your card collection), or you could use a custom priority file that specifies the priorities of
the morphs.
AnkiMorphs automatically finds .csv files placed
in [anki profile folder]/priority-files/.
Note: using
Collection frequencyis not recommended because it can be volatile; if you make any changes to your cards (delete, suspend, move, etc.), then a cascade of sorting changes can occur.
Read & Modify
If, for whatever reason, you don’t want AnkiMorphs to read one of the note filters you have set up, then you
can uncheck the Read option.
If you uncheck Modify, AnkiMorphs will analyze the
specified fields of cards (and update the database of known morphs based on them), but won’t reorder
or change the cards in any way.
Usage
There are some nuances that are important to be aware of when it comes to note filters:
Order of the note filters
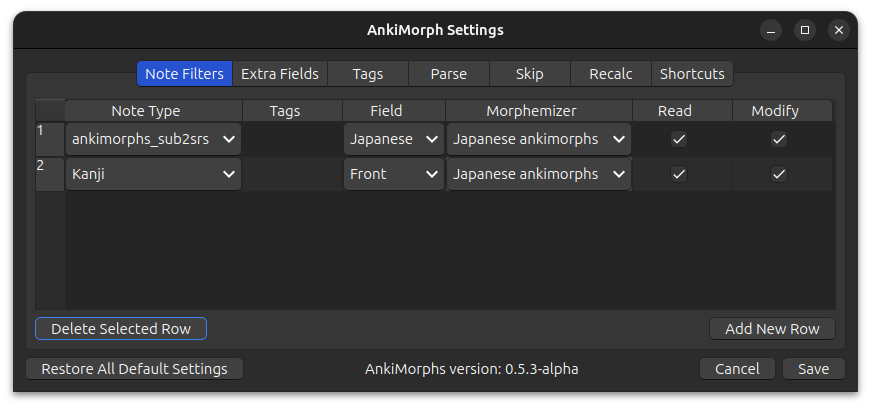
Order matters. In the image above all the cards that have note type japanese_sub2srs will have the text found in
the Japanese field analyzed, and then those cards will be sorted based on
the score of that text.
After those cards are analyzed and sorted then the next note filter will take effect: All the cards that have the
note type kanji will have the text found in the Front field analyzed and then those cards will be sorted based on
the score of that text.
Overlapping filters
If a card matches multiple filters, then it will only be analyzed and sorted based on the first matching filter. Any subsequent filters will not analyze and sort the card.
If you were to do something like this:
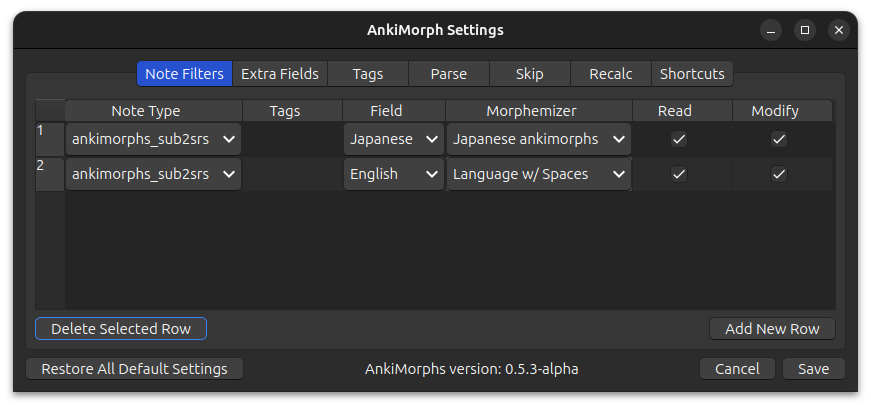
Then the second filter would do nothing because all the cards would have already been used by the first filter.
If you find yourself in a situation where you have overlapping note filters, then there are two things you can do:
- Make the filters more restrictive by using tags
- Create a new note type.
Tip: All your cards should follow the minimum information principle, not only will that help you remember them better, but it might make the note filters less complicated.
Extra Fields
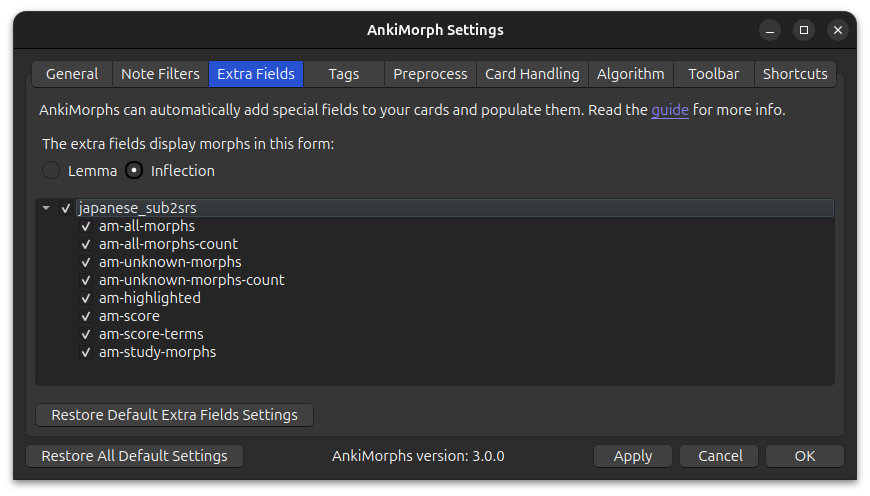
The text found in the note filter: field is extracted and analyzed by AnkiMorphs. AnkiMorphs can then place information about that text into dedicated fields on your cards.
Note: The first time you select an extra field, you will need to perform a full sync upload to AnkiWeb. If you have a large number of cards (500K+), syncing might become an issue. For more details, refer to the Anki FAQ.
Important: Extra fields add more data to your collection, so only select the fields that will be useful to you.
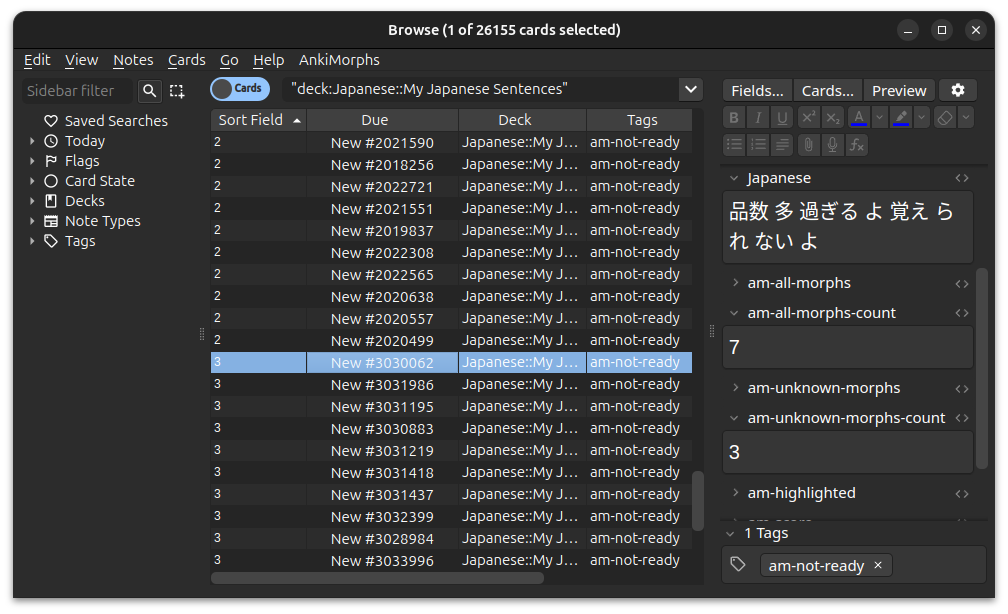
The fields contain the following:
-
am-all-morphs:
A list of the morphs. -
am-all-morphs-count:
The number of morphs. -
am-unknown-morphs:
A list of the morphs that are still unknown to you. -
am-unknown-morphs-count:
The number of morphs that are still unknown to you. -
am-highlighted:
An HTML version of the text that highlights the morphs based on learning status. -
am-score:
The score AnkiMorphs determined the card to have -
am-score-terms:
The individual score terms -
am-study-morphs:
A list of the morphs that were unknown to you when you first studied the card.
The following fields will only update on new cards:
- am-all-morphs
- am-all-morphs-count
- am-score
- am-score-terms
- am-study-morphs
and these fields will always update, even on reviewed cards:
- am-unknown-morphs
- am-unknown-morphs-count
- am-highlighted
Here is an example card where all the extra-fields have been selected:
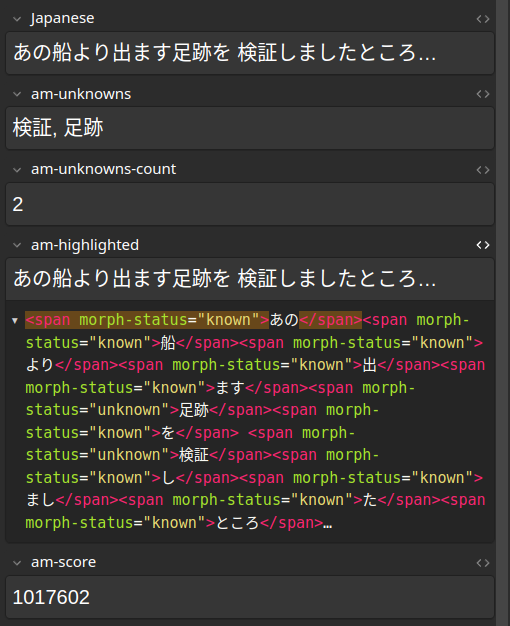
Extra fields display morphs in this form:
You can choose to display morphs in their inflected forms:
"walking and talking" -> [walking, and, talking]
or their lemma (base) forms:
"walking and talking" -> [walk, and, talk]
This effects the following three fields:
- am-all-morphs
- am-unknown-morphs
- am-study-morphs
Using am-study-morphs
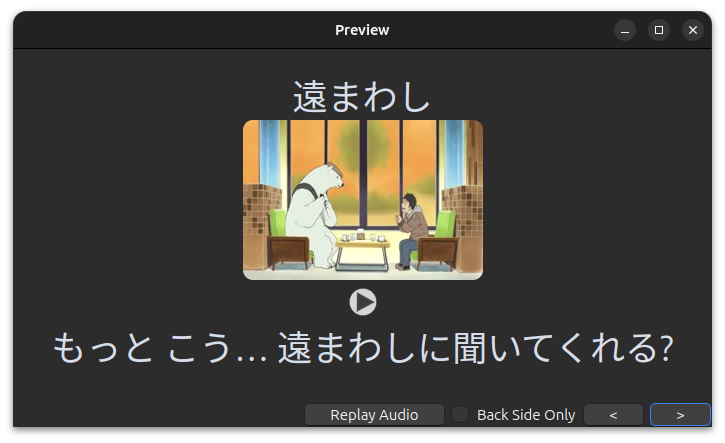
Adding this field to your card-template can give you a quick way to see which morphs are/were unknown to you on the first encounter. Here is a simplified version of the card template used in the example above:
Using am-*-morphs-count
This is useful if you want to sort your cards in the browser based on how many total/unknown morphs they have.
Using am-highlighted
This field is used for static highlighting. For more details, see the highlighting section.
Tags
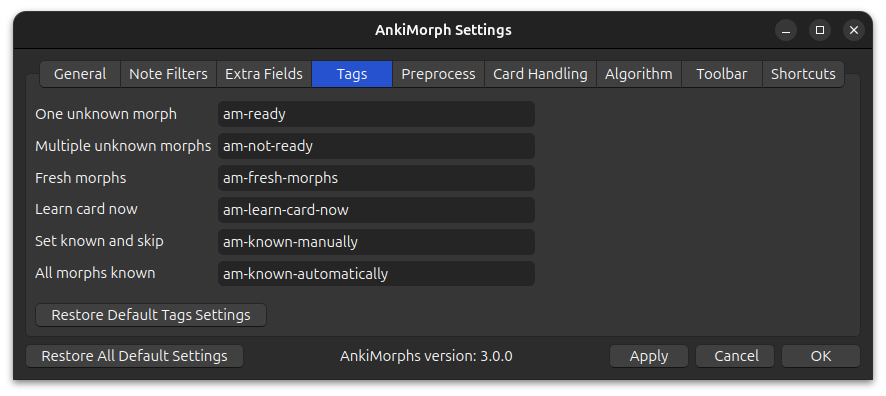
As AnkiMorphs processes cards, it automatically adds and removes various tags. You can customize the names of the different tags if you want, or you can leave them as they are and move on.
Note: Avoid reusing tags from other sources. Mixing different tags can quickly become complicated and confusing.
-
One unknown morph:
Cards that only have one unknown morph will be given this tag -
Multiple unknown morphs:
Cards that have more than one unknown morph will be given this tag -
Fresh morphs:
Cards that have one or more morphs in alearningstate will be given this tag -
Learn card now:
When you use the Learn Card Now feature on a card, it will be given this tag. The purpose of this tag is to make the internal process of theLearn Card Nowfeature simpler. Do not manually assign this tag to cards, as it will have no effect. -
Set known and skip:
When you use the Set Known and Skip feature on a card, it will be given this tag. Do not delete cards that have this tag, as AnkiMorphs relies on them to track which morphs you know. -
All morphs known:
New cards that only have morphs you already know will be given this tag. Cards with this tag can safely be deleted without AnkiMorphs losing track of which morphs you know. This can be useful if you want to trim down your card collection. -
Suspended automatically:
Cards that have been suspended with the suspend new cards option will be given this tag.
Preprocess
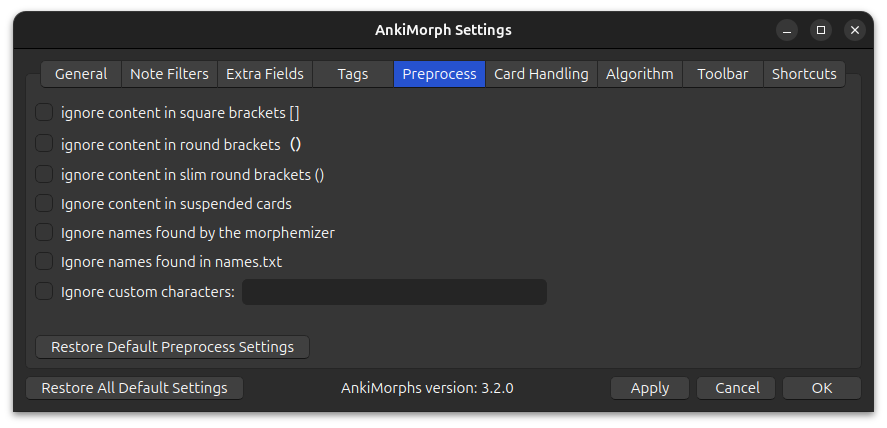
Here are some options that can preprocess the text on your cards, potentially removing uninteresting morphs for you.
-
Ignore content in square brackets []:
Ignore content such as furigana readings and pitch -
Ignore content in round brackets ():
Ignore content such as character names and readings in scripts -
Ignore content in slim round brackets( ):
Ignore content such as character names and readings in Japanese scripts -
Ignore content in suspended cards:
Ignore text found on suspended cards except for suspended cards that have the Set known and skip tag. This exception makes it so that you can safely suspend cards with known morphs without AnkiMorphs losing track of which morphs you know.Note: if you use collection frequency in any note filters, then you should not use this option because it will affect the morph priorities.
-
Ignore names found by the morphemizer:
Some morphemizers are able to recognize some names.Note: This can have mixed results; some morphemizers produce a non-trivial amount of false-positives, the German spaCy models in particular. If you find that there are missing morphs, then this is likely the cause. In that case you are probably better off only using the names.txt feature.
-
Ignore names found in names.txt:
Ignore names that are placed in names.txt -
Ignore numbers:
Note: Some morphemizers always ignore numbers regardless of this setting
-
Ignore custom characters:
Any characters you specify (e.g.,,.?@) will be ignored. This is especially useful when working with basic morphemizers like theSimple Space Splitter.
Card Handling
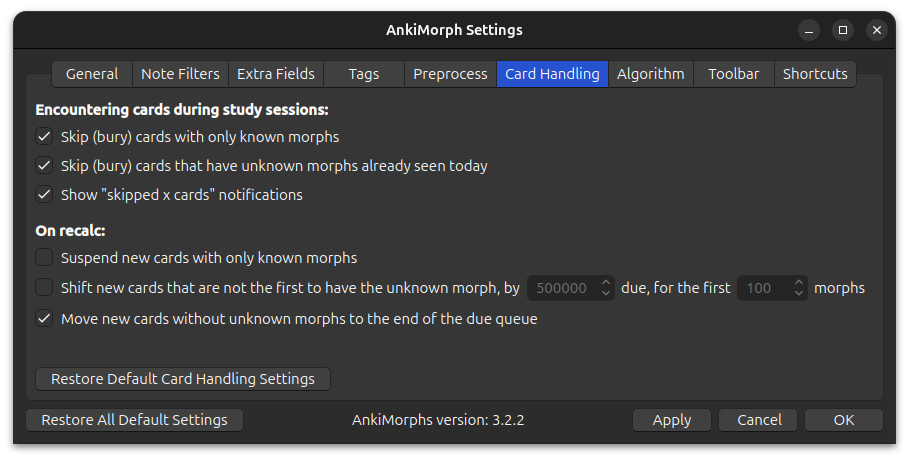
This is where you can make AnkiMorphs really efficient. AnkiMorphs sorts your cards based on how well you know its content; the more you know, the sooner the card will be shown. The downside is this is that it might take a long time before you see a cards with any unknown morphs, i.e., you don’t learn anything new.
To overcome this problem and speed up the learning process, we can use the options found here.
When Encountering Cards (skip = bury)
-
Skip cards that have no unknown morphs:
If AnkiMorph has determined that there are no unknown morphs on the card, then it will be buried and skipped.-
Don’t skip if they contain fresh morphs:
Choose this if you want to study more fresh/recently learned morphs. -
Skip even if they contain fresh morphs:
Choose this if you want maximum efficiency and you don’t feel the need to reinforce fresh/recently learned morphs.
-
-
Skip cards that have unknown morphs already seen today:
If you have already studied a card earlier today with the same unknown morph, then any subsequent cards with that unknown morph will be buried and skipped, which reduces the need to Recalc. -
Show notification “Skipped x cards”:
After cards are skipped, a notification in the lower left corner displays how many cards were skipped and for what reason. If you don’t want to see this notification, you can uncheck this option.
On Recalc
-
Suspend new cards::
Note: AnkiMorphs never unsuspends cards. As a result, these cards are never error-corrected, which can lead to overestimating known morphs and reduce practice efficiency. Consider using the
Move new cards to the end of the due queueoption instead.This option suspends certain new cards, which can prevent having to skip the same cards at the start of every session. These cards are given the suspended automatically tag.
-
If all morphs are known:
Suspends new cards that have no unknown morphs, except if they include fresh morphs. -
If all morphs are known or fresh:
Suspends new cards that have no unknown morphs, even if they include fresh morphs.
-
-
Move new cards to the end of the due queue:
This option pushes certain new cards to the very end of the study queue, which can prevent having to skip the same cards at the start of every session. These cards are assigned aduevalue of2047483647.-
If all morphs are known:
Moves new cards that have no unknown morphs, except if they include fresh morphs. -
If all morphs are known or fresh:
Moves new cards that have no unknown morphs, even if they include fresh morphs.
-
-
Shift new cards that are not the first to have the unknown morph:
This option is an alternative to the skip options that are only available on desktop, potentially making it easier to study new cards on mobile.
There are two parameters you can adjust:- How much to shift/offset the due of the affected cards
- How many unknown morphs to perform this shift/offset on
Here is an example card order without this option activated:Card ID Unknown Morph Due Card_1 break 50 001 Card_2 break 50 002 Card_3 walk 50 003 Card_4 walk 50 004
Here are the same cards but with this option activated (due_shift = 50 000, first_morphs = 2):Card ID Unknown Morph Due Card_1 break 50 001 Card_3 walk 50 003 Card_2 break 100 002 Card_4 walk 100 004
Algorithm
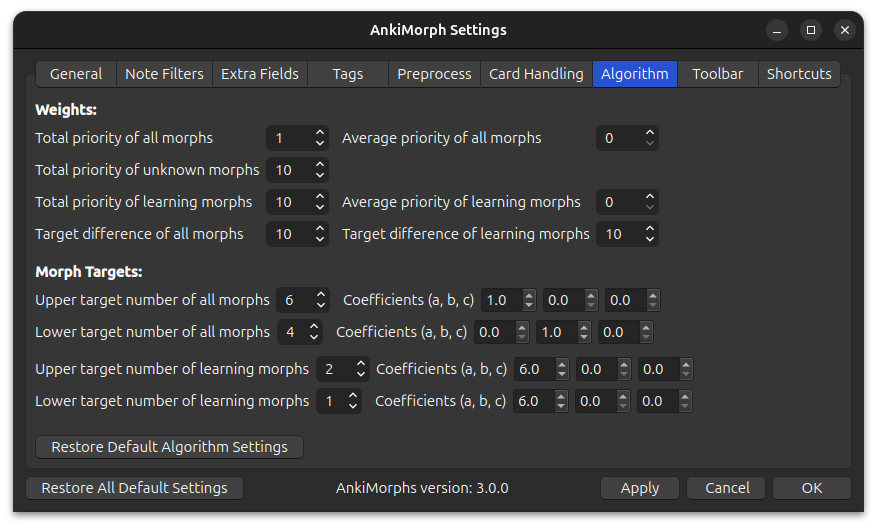
For these settings to make sense you have to read the scoring algorithm section first.
Weights
-
Total priority of all morphs:
The \(\large W_{\text{total}}^{\text{all}}\) weight in \(\mathbf{W_P}\) -
Total priority of unknown morphs:
The \(\large W_{\text{total}}^{\text{unknown}}\) weight in \(\mathbf{W_P}\) -
Total priority of learning morphs:
The \(\large W_{\text{total}}^{\text{learning}}\) weight in \(\mathbf{W_P}\) -
Target difference of all morphs:
The \(\large W_{\text{target}}^{\text{all}}\) weight in \(\mathbf{W_D}\) -
Average priority of all morphs:
The \(\large W_{\text{average}}^{\text{all}}\) weight in \(\mathbf{W_P}\) -
Average priority of learning morphs:
The \(\large W_{\text{average}}^{\text{learning}}\) weight in \(\mathbf{W_P}\) -
Target difference of learning morphs:
The \(\large W_{\text{target}}^{\text{learning}}\) weight in \(\mathbf{W_D}\)
Morph Targets
These are explained in the scoring algorithm: deviation section.
Play around with the variables here: https://www.geogebra.org/graphing/ta3eqb8y
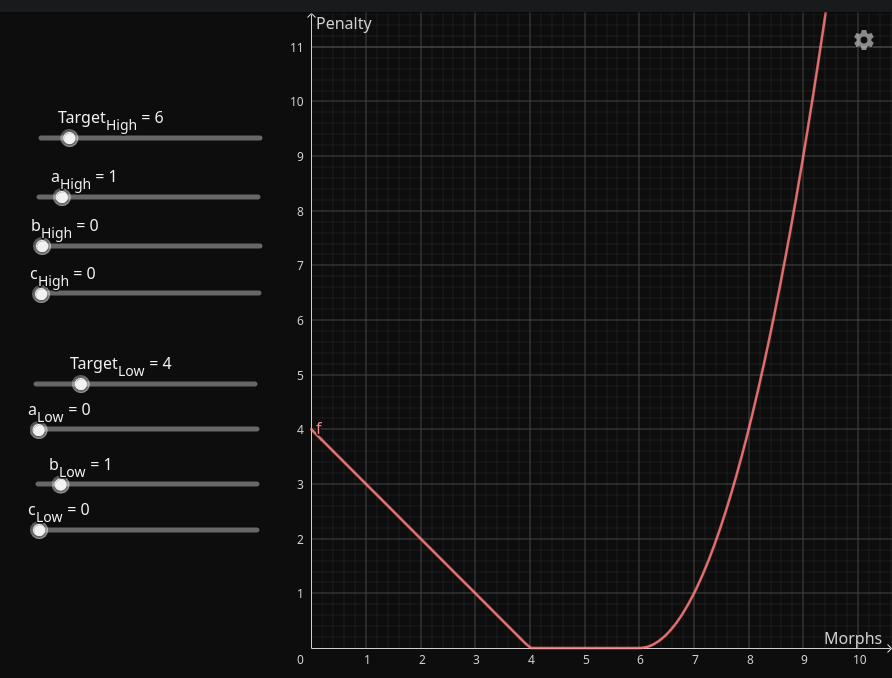
This is what the default \(\large D_{\text{target}}^{\text{all}}\) looks like:
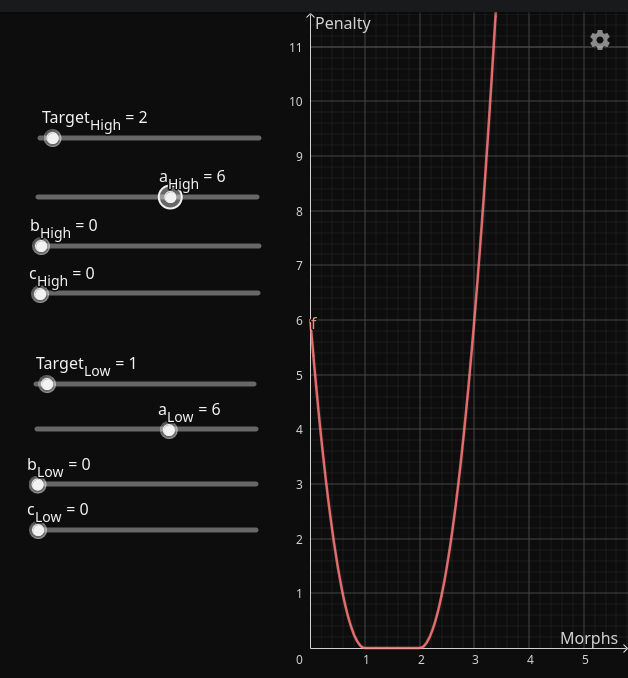
And the default \(\large D_{\text{target}}^{\text{learning}}\) looks like this:
Sorting Cards in the Exact Same Order as a Priority File
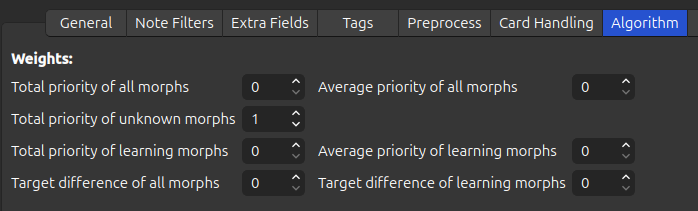
If you only want to sort the cards based on the order of a priority file, disable all the weights except for \(W_{\text{total}}^{\text{unknown}}\). This can be especially useful if you are using a study plan.
Shortcuts
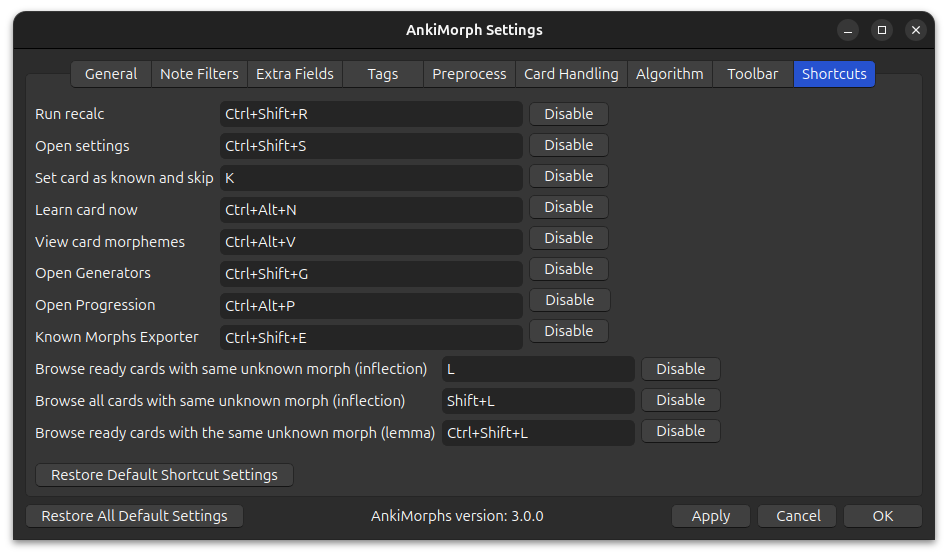
Change the AnkiMorph shortcuts if you prefer different ones. Be aware that changing these might lead to unexpected behavior.
Prioritizing
The more frequently a morph occurs in a language, the more useful it is to learn. This is the fundamental principle behind AnkiMorphs–learn a language in the order that will be the most useful.
AnkiMorphs is a general purpose language learning tool, therefore, it has to be told which morphs occur most often. You
can do this in two ways, either have AnkiMorphs calculate the morph frequencies found in your
cards (Collection frequency), or you can specify a custom .csv file that contains that information.
Any .csv file located in the folder [anki profile folder]/priority-files/ is
available for selection in note filters: morph priority.
But before we outline the custom priority files, we have to discuss morph lemmas and inflections.
Lemmas or Inflections?
There are scenarios where you might not want to give each individual inflection a separate priority:
-
Chinese technically does not have inflections, so any inflection data is artificial and leads to a wasteful use of resources.
-
Korean has an extreme number of inflections, leading to an explosion of priorities, which creates disproportionate penalties.
-
You might feel that you have a good enough grasp of the grammar of inflections, making it unnecessary to prioritize one over another.
If you never want to give separate priorities to inflections then you should choose a lemma only priority file. If you do care about inflection priorities, or if you might want to switch to lemma priorities on the fly, then choose an inflection priority file.
Custom Priority Files
You can use the Priority File Generator or the Study Plan Generator to create your own custom priority file, or you can download some pre-made ones at the bottom of this page.
Note:
- The
Occurrencescolumn is optional- Any lines after 1 million will be ignored by AnkiMorphs
Custom Lemma Priority Files
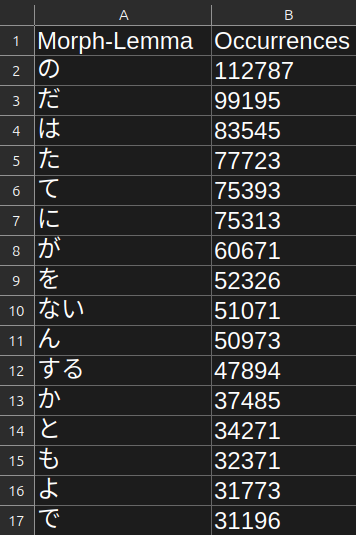
The lemma only priority files follows this format:
- The first row contains column headers.
- The second row and down contain morph lemmas in descending order of frequency.
Custom Inflection Priority Files
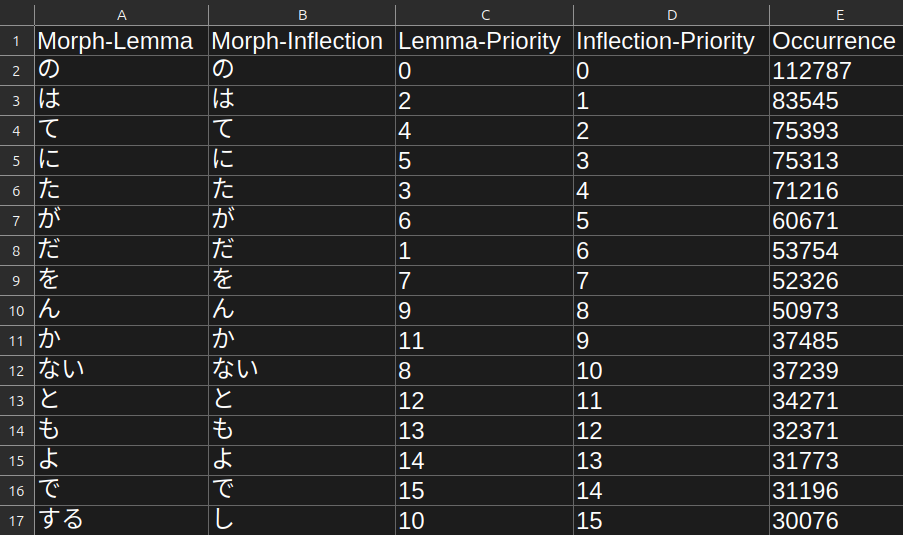
The inflection priority files follows this format:
- The first row contains column headers.
- The second row and down contain morphs in descending order of inflection frequency.
- The first column contains morph-lemmas, the second column contains morph-inflections (this is done to prevent morph collisions).
- The third column contains lemma priorities, the fourth column contains inflection priorities (this is done to so you can switch morph evaluation on the fly).
Morph Collision
Inflected morphs can be identical even if they are derived from different lemmas (base), e.g.:
Lemma : Inflection
有る ある
或る ある
To prevent misinterpretation of the inflected morphs, we also store the lemmas.
Downloadable Priority Files
Unless stated otherwise, these are inflection priority files, generated using a 90% comprehension cutoff.
Cantonese
Note: This is a lemma only priority file that was not generated using AnkiMorphs, so it might not work very well (or at all).
- zhh-freq.csv
- Source:
existingwordcount.csvfound on words.hk - analysis
Catalan
- ca-news-priority.csv
- Source:
cat_news_2022_300K-sentences.txtfound on wortschatz - catalan corpora- Morphemizer:
spaCy: ca-core-news-sm
Chinese
Note: this is a lemma only priority file.
- zh-news-lemma-priority.csv
- Source:
zho_news_2020_300K-sentences.txtfound on wortschatz - chinese corpora- Morphemizer:
AnkiMorphs: Chinese
Croatian
- hr-news-priority.csv
- Source:
hrv_news_2020_300K-sentences.txtfound on wortschatz - croatian corpora- Morphemizer:
spaCy: hr-core-news-sm
Danish
- da-news-priority.csv
- Source:
dan_news_2022_300K-sentences.txtfound on wortschatz - danish corpora- Morphemizer:
spaCy: da-core-news-sm
Dutch
- nl-news-priority.csv
- Source:
nld_news_2022_300K-sentences.txtfound on wortschatz - dutch corpora- Morphemizer:
spaCy: nl-core-news-sm
English
- en-wiki-priority.csv
- Source:
eng_wikipedia_2016_300K-sentences.txtfound on wortschatz - english corpora- Morphemizer:
spaCy: en-core-web-sm
Finnish
- fi-news-priority.csv
- Source:
fin_news_2022_300K-sentences.txtfound on wortschatz - finnish corpora- Morphemizer:
spaCy: fi-core-news-sm
French
- fr-news-priority.csv
- Source:
fra_news_2022_300K-sentences.txtfound on wortschatz - french corpora- Morphemizer:
spaCy: fr-core-news-sm
German
- de-news-priority.csv
- Source:
deu_news_2022_300K-sentences.txtfound on wortschatz - german corpora- Morphemizer:
spaCy: de-core-news-md
Greek (Modern)
- el-news-priority.csv
- Source:
ell_news_2022_300K-sentences.txtfound on wortschatz - modern greek corpora- Morphemizer:
spaCy: el-core-news-sm
Italian
- it-news-priority.csv
- Source:
ita_news_2022_300K-sentences.txtfound on wortschatz - italian corpora- Morphemizer:
spaCy: it-core-news-sm
Japanese
- ja-news-priority.csv
- Source:
jpn_news_2011_300K-sentences.txtfound on wortschatz - japanese corpora- Morphemizer:
AnkiMorphs: Japanese- ja-anime-priority.csv
- Source: NanakoRaws
- Morphemizer:
AnkiMorphs: Japanese
Korean
Note: this is a lemma only priority file.
- ko-news-lemma-priority.csv
- Source:
kor_news_2022_300K-sentences.txtfound on wortschatz - korean corpora- Morphemizer:
spaCy: ko-core-news-sm
Lithuanian
- lt-news-priority.csv
- Source:
lit_news_2020_300K-sentences.txtfound on wortschatz - lithuanian corpora- Morphemizer:
spaCy: lt-core-news-sm
Macedonian
- mk-news-priority.csv
- Source:
mkd_newscrawl_2011_300K-sentences.txtfound on wortschatz - macedonian corpora- Morphemizer:
spaCy: mk-core-news-sm
Norwegian (Bokmål)
- nb-news-priority.csv
- Source:
nob_news_2013_300K-sentences.txtfound on wortschatz - norwegian corpora- Morphemizer:
spaCy: nb-core-news-sm
Polish
- pl-news-priority.csv
- Source:
pol_news_2022_300K-sentences.txtfound on wortschatz - polish corpora- Morphemizer:
spaCy: pl-core-news-sm
Portuguese
- pt-news-priority.csv
- Source:
por_news_2022_300K-sentences.txtfound on wortschatz - portuguese corpora- Morphemizer:
spaCy: pt-core-news-sm
Romanian
- ro-news-priority.csv
- Source:
ron_news_2022_300K-sentences.txtfound on wortschatz - romanian corpora- Morphemizer:
spaCy: ro-core-news-sm
Russian
- ru-web-priority.csv
- Source:
rus-ru_web-public_2019_300K-sentences.txtfound on wortschatz - russian corpora- Morphemizer:
spaCy: ru-core-news-sm
Slovenian
- sl-news-priority.csv
- Source:
slv_news_2020_300K-sentences.txtfound on wortschatz - slovenian corpora- Morphemizer:
spaCy: sl-core-news-sm
Spanish
- es-news-priority.csv
- Source:
spa_news_2022_300K-sentences.txtfound on wortschatz - spanish corpora- Morphemizer:
spaCy: es-core-news-sm
Swedish
- sv-news-priority.csv
- Source:
swe_news_2022_300K-sentences.txtfound on wortschatz - swedish corpora- Morphemizer:
spaCy: sv-core-news-sm
Ukrainian
- uk-news-priority.csv
- Source:
ukr_news_2022_300K-sentences.txtfound on wortschatz - ukrainian corpora- Morphemizer:
spaCy: uk-core-news-sm
Names
Note:
- Memory Usage: AnkiMorphs loads the entire list of names into memory and compares against it each time you review a card. To avoid slowdowns, keep the list of names as small as possible.
- Loading Changes: If you manually edit the
names.txtfile, you must restart Anki for the changes to take effect. However, if you use theMark as namefeature, no restart is required.
You can have AnkiMorphs automatically filter out specified names found on your cards. This feature is designed so users won’t have to learn the names of places or individuals, as these words lack inherent meaning that can be acquired.
You can activate the feature by selecting Ignore names found in names.txt it in
the preprocess settings.
The names.txt file is located in your anki profile folder.
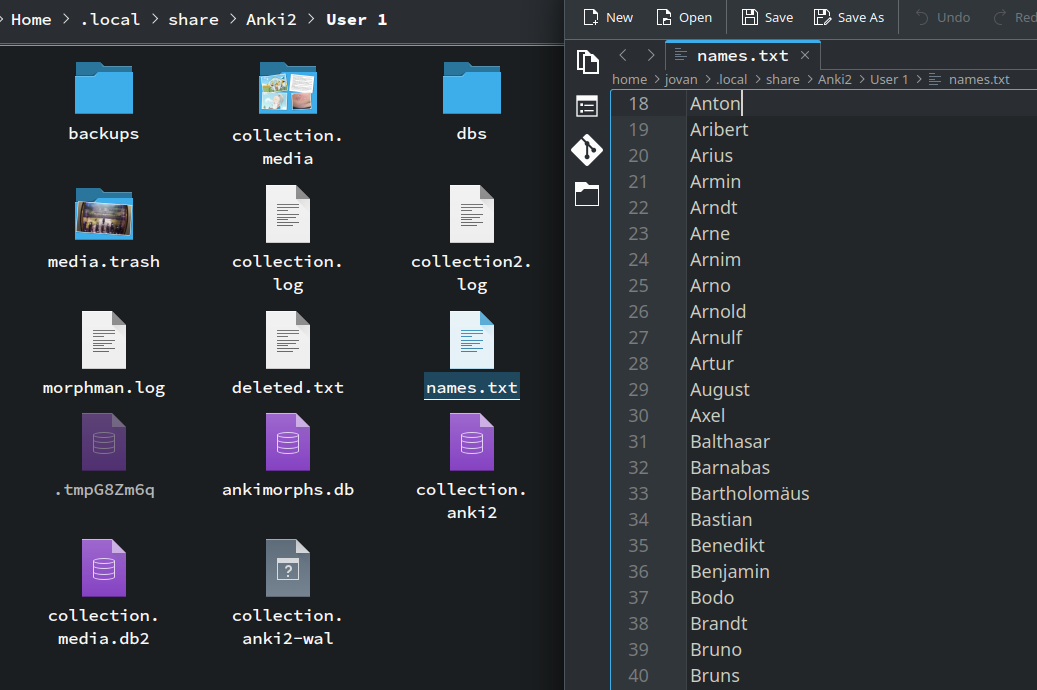
You can either update this file manually, or during a review you can also add names to the list by selecting a word,
right-clicking it, and choosing Mark as name from the dropdown menu.
Setting Known Morphs
AnkiMorphs determines which morphs you know by analyzing the cards you specify. However, if you delete any of those
cards then it can lead to loss of information. To address this issue, you can store known morphs in .csv files in the
[anki profile]/known-morphs folder.
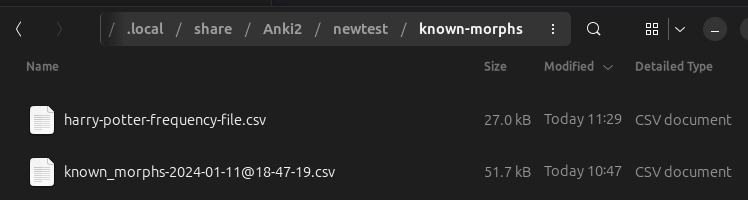
Any .csv file that has the priority file format (like those produces by the
Known Morphs Exporter), and is placed within this folder, can be read during Recalc and saved to the database.
You can activate this feature by selecting Read files in 'known-morphs' folder and register morphs as known
in the general settings tab.
Highlighting
AnkiMorphs can automatically color-code morphs based on their learning status, i.e., how well you know them.
I recommend only putting the highlighted-field on the back of cards. The reason for this is that, in order to get the best results, you want your SRS experience to simulate real life as much as possible. When reading in real life, you aren’t going to be told which words you know and which you don’t. So, it makes sense to have your sentence cards reflect this.
The highlighting can be done in two ways, the text can either be dynamically highlighted (just-in-time) whenever you encounter it, or by adding a static extra field to your cards that only updates when using Recalc.
Static vs Dynamic
Both options have their tradeoffs, and you should evaluate them before deciding which one to use.
| Static | Dynamic | |
|---|---|---|
| Works on mobile | Yes | No |
| Can make viewing cards slower | No | Yes |
| Increases collection size | Yes | No |
| Increases sync duration | Yes | No |
| Requires modifying cards | Yes | No |
| Slower Recalc | Yes | No |
For highlighting to work, the cards must match a note filter. However, for
dynamic highlighting, the note filter does not need the read or modify options enabled. This means you can
apply highlighting to cards without sorting them.
For the static highlighting to work you have to also enable the am-highlighted extra field.
Now we have to update the card templates and styling.
Changing Your Card Templates
Here is a simplified template of the card shown above without any highlighting:
To add dynamic highlighting to the back of the card we prepend am-highlight: to the Japanese field:
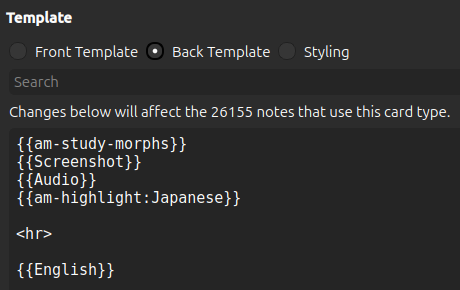
To add static highlighting to the back of the card we replace the Japanese field with am-highlighted
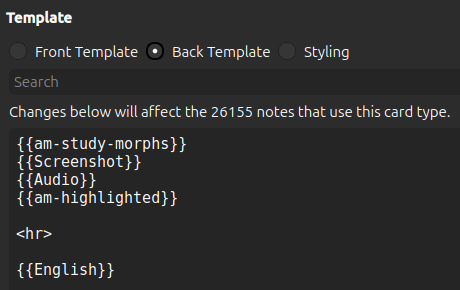
We also need to update the styling section to specify which colors we want the morphs to have.
Changing Your Card Styling
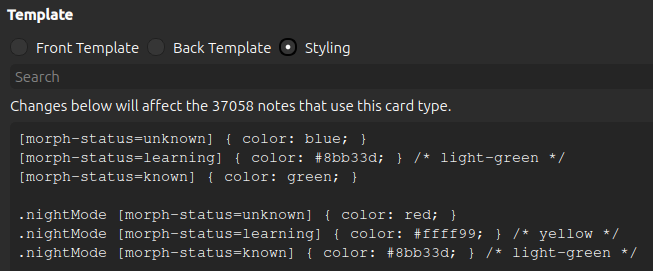
You can pick and choose among these; if you only want unknown morphs to be highlighted, and you don’t care about dark-mode, then only adding the first line would be enough. You can also change the colors to anything you want.
[morph-status=unknown] { color: blue; }
[morph-status=learning] { color: #8bb33d; } /* light-green */
[morph-status=known] { color: green; }
[morph-status=undefined] { color: grey; }
.nightMode [morph-status=unknown] { color: red; }
.nightMode [morph-status=learning] { color: #ffff99; } /* yellow */
.nightMode [morph-status=known] { color: #8bb33d; } /* light-green */
.nightMode [morph-status=undefined] { color: grey; }
It’s also possible to use background-color:
[morph-status=unknown] { background-color: blue; }
[morph-status=learning] { background-color: #8bb33d; } /* light-green */
[morph-status=known] { background-color: green; }
[morph-status=undefined] { background-color: grey; }
.nightMode [morph-status=unknown] { background-color: red; }
.nightMode [morph-status=learning] { background-color: #ffff99; } /* yellow */
.nightMode [morph-status=known] { background-color: #8bb33d; } /* light-green */
.nightMode [morph-status=undefined] { background-color: grey; }
Ruby Character Filters
Note: The
Ignore content in square bracketspreprocess setting option needs to be activated for ruby character highlighting to function properly.
Anki supports ruby characters (pronunciation annotations) such as furigana. You can choose how these are displayed by prepending the respective character filter to the field on the card template. The native character filters work on the static highlighting, and for the dynamic highlighting we have corresponding custom filters.
| Static | Dynamic | |
|---|---|---|
| Kanji only | kanji: | am-highlight-kanji: |
| Kana only | kana: | am-highlight-kana: |
| Furigana | furigana: | am-highlight-furigana: |
Here is an example of what they all look like:
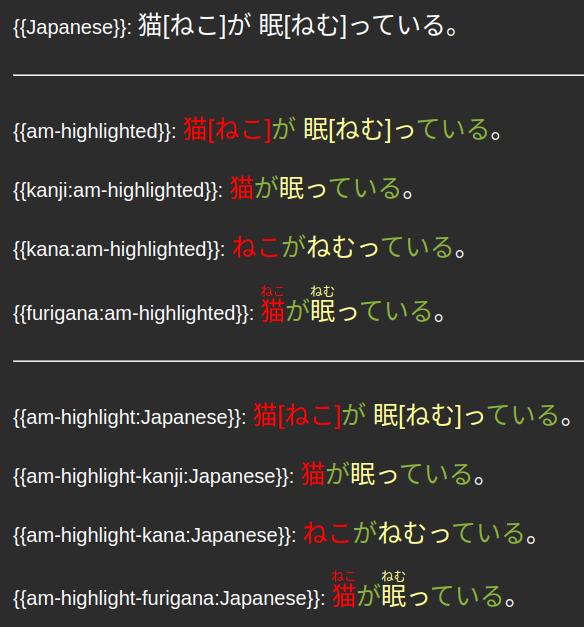
Duplicate Audio Problem
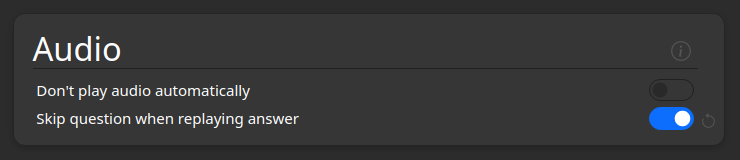
When the back of a card also has an audio field and not just the front, then both might play after each other when you
press Show Answer on the card. To prevent both playing you can do the following:
- Go to deck-options
- Scroll down to the
Audiosection - Activate
Skip question when replaying answer
Usage
After you have finished installing and setting up, you can run Recalc and finally start using AnkiMorphs with your cards! Delve into how to use AnkiMorphs with the following sections:
- Reviewing cards with AnkiMorphs.
- Using the Browser Options.
- Generating priority files to change morph priorities.
- Generating readability reports to find out much of specified files you will be able to read.
- Exporting known morphs so you can trim down your card collection.
- Gauging your overall progress in terms of morph priorities.
Recalc
Recalc is short for “recalculate”, and is basically the command that tells AnkiMorphs to work all its magic. When you run Recalc, AnkiMorphs will go through the cards that match any ‘Note Filter’ and do the following:
- Update the
ankimorphs.dbwith any new seen morphs, known morphs, etc. - Calculate the score of the cards, and then sort the cards based on that score.
- Update any cards’ extra fields and tags.
Basically, when you run Recalc, AnkiMorphs will go through your collection, recalculate the difficulty of your cards based on your new knowledge, and reorder your new cards in a way that’s optimal for the new you: the you who knows more than you did yesterday.
You can run Recalc as often as you like, but you should run it at least once before or after every study session so that your new cards will appear in the optimal order.
It’s easy to forget to run recalc, so you can also
check the Recalc on sync settings option, which will take care of recalc for you by
running it automatically before Anki syncs your collection.
Note: Recalc can potentially reorganize all your cards, which can cause long sync times. The Anki FAQ has some tricks you can try if this poses a significant problem.
Scoring Algorithm
TL;DR: Low scores are good, high scores are bad.
The order in which new cards are displayed depends on their due value: a card with due = 1 will be shown before a card with due = 2,
and so on. Leveraging this property, we can implement the following strategy: assign higher due values to cards with more complex
text, pushing them further back in the card queue. Here are some examples of what that might look like:
- “She walked home”
due = 600
- “Asymmetric catalysis for the enantioselective synthesis of chiral molecules”
due = 100 000 000
Now, let’s define some properties that we want our cards to have:
- Few unknowns morphs (comprehensibility)
- High priority morphs (significance)
- Ideal length (low deviation)
We can now invert these properties to calculate a “penalty” score, which will then replace the due values of the cards.
That formula at the highest level is:
\[ \large \text{score} = \text{incomprehensibility} + \text{insignificance} + \text{deviation} \]
Let’s break it down into smaller components.
incomprehensibility
In practice, the comprehensibility of a given text is determined by a combination of known grammar points and vocabulary. However, evaluating grammar is non-trivial, especially in a general language learning context, so we will not make any explicit attempts to do so.
Determining which morphs are known is relatively easy, so our incomprehensibility score will be the product of the number of unknown morphs and a constant penalty factor.
\[ \large \text{incomprehensibility} = PU \times \left| M_{\text{U}} \right| \]
where \[ {\large \begin{align*} & PU: \text{penalty for unknown} = 10^6\\ & M: \text{set of identified morphs} \\ & m_{\text{li}}: \text{morph learning interval} \\ & M_U: \text{unknown morphs} = { m \in M \mid m_{\text{li}} = 0 } \\ \end{align*} } \]
insignificance
Each morph has a priority value, which AnkiMorphs aggregates into the following metrics: \[ {\Large \begin{array}{ccc} \begin{aligned} \\[15pt] P_{\text{total}}^{\text{all}} &= \sum_{m \in M}{m_p} \\[20pt] P_{\text{total}}^{\text{unknown}} &= \sum_{m \in M_{\text{U}}}{m_p} \\[20pt] P_{\text{total}}^{\text{learning}} &= \sum_{m \in M_{\text{L}}}{m_p} \\ \end{aligned} & & \begin{aligned} \\[1pt] P_{\text{average}}^{\text{all}} &= \frac{P_{\text{total}}^{\text{all}}}{\left| M \right|} \\[20pt] \\[25pt] P_{\text{average}}^{\text{learning}} &= \frac{P_{\text{total}}^{\text{learning}}}{\left| M_{\text{L}} \right|} \ \end{aligned} \end{array} } \]
where \[ {\large \begin{align*} & m_{\text{p}}: \text{morph priority} \\ & M_{\text{L}}: \text{learning morphs} = { m \in M \mid 0 < m_{\text{li}} < \text{known threshold} } \\ \end{align*} } \]
Note: \(\large P_{\text{average}}^{\text{unknown}}\) is not included since it would not have any meaningful impact on 1T cards.
You can customize the algorithm by selecting any combination of these metrics and adjusting their influence on the result by changing their corresponding weights. This is done using two column vectors: one for the weights and one for the aggregated metrics. The final score is computed by taking the scalar product of these vectors:
\[ {\large \mathbf{W_P} = \begin{pmatrix} \begin{array}{l} W_{\text{total}}^{\text{all}} \\[10pt] W_{\text{total}}^{\text{unknown}} \\[10pt] W_{\text{total}}^{\text{learning}} \\[10pt] W_{\text{average}}^{\text{all}} \\[10pt] W_{\text{average}}^{\text{learning}} \\[10pt] \end{array} \end{pmatrix} \quad \mathbf{P} = \begin{pmatrix} \begin{array}{l} P_{\text{total}}^{\text{all}} \\[10pt] P_{\text{total}}^{\text{unknown}} \\[10pt] P_{\text{total}}^{\text{learning}} \\[10pt] P_{\text{average}}^{\text{all}} \\[10pt] P_{\text{average}}^{\text{learning}} \\[10pt] \end{array} \end{pmatrix} } \]
which gives us: \[ \large \text{insignificance} = W_P \cdot P = w_1 p_1 + w_2 p_2 + \cdots + w_n p_n = \sum_{i=1}^{n} w_i p_i \]
Example:
\[ {\large \mathbf{W_P} = \begin{pmatrix} \begin{array}{c} 10 \\[10pt] 0 \\[10pt] 0 \\[10pt] 0 \\[10pt] 5 \\[10pt] \end{array} \end{pmatrix} \quad \mathbf{P} = \begin{pmatrix} \begin{array}{c} 600 \\[10pt] 30 \\[10pt] 20 \\[10pt] 100 \\[10pt] 10 \\[10pt] \end{array} \end{pmatrix} } \]
\[ \large W_P \cdot P = 10 \times 600 + 0 \times 30 + 0 \times 20 + 0 \times 100 + 5 \times 10 = 6050 \]
Deviation
Learning can be easier with more surrounding context, e.g., other known words. However, if a sentence contains too many words, learning may become more challenging. This is because the complexity of the grammar often increases, along with the likelihood of not perfectly remembering all the surrounding words. Ideally, we want our cards to have sentences within this optimal range.
Having the ability to bias our sentences towards a certain length is also beneficial; you might find it easier to learn from shorter sentences compared to longer ones, or vice versa.
To achieve this, we use a piecewise equation that where we define the following:
- How much to penalize excessive morphs
- How much to penalize insufficient morphs
- The ideal range (target) of morphs
Here is an example of what that might look like:
Playground: https://www.geogebra.org/graphing/ta3eqb8y
This graph shows:
- Penalty for excessive morphs: squared in relation to the target difference
- Penalty for insufficient morphs: linear in relation to the target difference
- Ideal range (target): 4-6 morphs
AnkiMorphs provides the following metrics, which you can influence by changing the coefficients:
\[ {\large D_{\text{target}}^{\text{all}} = \begin{cases} \lceil a_H (|n - T_H|^2) + b_H |n - T_H| + c_H\rceil & \text{if } n > T_H \\ \lceil a_L (|n - T_L|^2) + b_L |n - T_L| + c_L\rceil & \text{if } n < T_L \\ 0 & \text{otherwise} \end{cases} } \]
\[ {\large D_{\text{target}}^{\text{learning}} = \begin{cases} \lceil a_H (|n_L - T_H|^2) + b_H |n_L - T_H| + c_H\rceil & \text{if } n_L > T_H \\ \lceil a_L (|n_L - T_L|^2) + b_L |n_L - T_L| + c_L\rceil & \text{if } n_L < T_L \\ 0 & \text{otherwise} \end{cases} } \]
where \[ {\large \begin{align*} & D_{\text{target}}: \text{target difference} \\ & \lceil \; \rceil: \text{round up to the nearest integer} \\ & T_H: \text{high target} \\ & T_L: \text{low target} \\ & n: \text{number of morphs} = \left| M \right|\\ & n_L: \text{number of learning morphs} = \left| M_{\text{L}} \right| \\ & a_H, b_H, c_H : \text{coefficients when \( n \) or \( n_L \) is greater than \( T_H \)} \\ & a_L, b_L, c_L : \text{coefficients when \( n \) or \( n_L \) is less than \( T_L \)} \\ \end{align*} } \]
with the following vectors:
\[ {\large \mathbf{W_D} = \begin{pmatrix} \begin{array}{l} W_{\text{target}}^{\text{all}} \\[10pt] W_{\text{target}}^{\text{learning}} \\[10pt] \end{array} \end{pmatrix} \quad \mathbf{D} = \begin{pmatrix} \begin{array}{l} D_{\text{target}}^{\text{all}} \\[10pt] D_{\text{target}}^{\text{learning}} \\[10pt] \end{array} \end{pmatrix} } \]
which gives us: \[ \large \text{deviation} = W_D \cdot D = \sum_{i=1}^{n} w_i d_i \]
Constraints
We have now refined the formula to:
\[ {\large \begin{align*} \text{score} &= \text{incomprehensibility} + \text{insignificance} + \text{deviation}\\ \text{score} &= PU \times \left| M_{\text{U}} \right| + W_P \cdot P + W_D \cdot D \end{align*} } \]
However, there are a few practical concerns we have to address.
First, we need to ensure that cards are primarily ordered by the number of unknown morphs they contain. This means that all 1T cards should appear before any MT cards, regardless of their insignificance or deviation.
To do this, we apply a min function to ensure that the sum of the last two terms does not exceed \(PU - 1\)
\[
\large \text{score} = PU \times \left| M_{\text{U}} \right| + \min \left(W_P \cdot P + W_D \cdot D,\ PU - 1\right)
\]
where \[ {\large \begin{align*} & \min: \text{choose the side that has the smallest number} \ \end{align*} } \]
Lastly, we have to make sure that the score does not exceed the maximum card due value allowed by Anki. The due value
is stored as a signed 32-bit integer, with a maximum value of \(2^{31} - 1\). To prevent overflow when cards are shifted,
we include a safety margin of \(10^8\). This results in the upper bound:
\[ \large \text{score}_{\text{max}} = 2^{31} - 1 - 10^8 \]
Now we wrap the entire expression in another min function to get our final formula:
\[ \large \text{score} = \min \left(PU \times \left| M_{\text{U}} \right| + \min \left(W_P \cdot P + W_D \cdot D,\ PU - 1\right),\ \text{score}_{\text{max}} \right) \]
Reviewing Cards
Starting Out
When you first start using AnkiMorphs, you will probably come across many variations of Interjections (e.g. Aaah!,
umm..., Wow!) and other uninteresting
words. Just tag them as known
and move on. When you reach a critical mass of known morphs, usually around 50–100, is when you will start encountering
useful sentences.
Stuttered names or words might accidentally produce morphs that don’t make any sense in the context, and you should probably suspend these cards or mark them as known if there are many of them.
AnkiMorphs might seem error-prone at first, like mixing up two (seemingly) different morphs, but the more data it accumulates, the more accurate it becomes, so try not to get discouraged! It becomes much more enjoyable to use after you know 100+ morphs.
It is a good idea to frequently Recalc when you are first starting out, maybe every 10 cards or so, to make sure you get the best possible new cards.
Encountering Morphs You Already Know
If you already know the morphs in a card you are presented, then use the hotkey K (for Known) to add
the am-known-manually tag to the card and skip it. The morphs on this card will be considered known the next time you
recalc.
Encountering Cards You Don’t Understand
There will also be times when AnkiMorphs says a card is 1T, but you aren’t able to understand it. There are two reasons this may occur. The first is that, due to incorrect parsing, AnkiMorphs thinks you know a word that you don’t. Unfortunately, there is no easy way to remove morphs from the AnkiMorphs’ database. Luckily, this shouldn’t happen very often. When it does, your only real option is to suspend or delete the card.
The other scenario is that you aren’t able to understand a sentence deemed 1T despite it indeed containing only one unknown morph. This is simply a fact of life when it comes to language learning. Sometimes you know all the words in a sentence, but still just can’t get what it means. It could be due to many things, such as one of the words having an alternate meaning you haven’t learned yet, or the grammar being too tricky for you to parse at your current level. Basically, although the sentence appears to be 1T, it’s actually MT. By definition, any sentence that’s truly 1T shouldn’t be difficult to understand.
Whenever this happens, it’s best to either find a better card or suspend/delete theccard and move on. The whole point of AnkiMorphs is to help you make fast progress by collecting low-hanging fruit. If you spend time mulling over things that are above your level, you’re defeating the purpose of the add-on.
Finding A Better Card
If you want to learn a different card instead of the one you are presented, then press the hotkey
L to open the browser and see all the other 1T cards in your collection with the same
unknown morph. If you want to see all 1T and MT cards you can use Shift+L.
From here you can right-click your preferred card and select Learn Card Now. You can also find the same options in
the AnkiMorphs menu at the top of the browse window.
The card will then go to the top of the new cards-queue. If you have other due cards, then they might show up first.
Encountering Suitable 1T Cards
If you come across a new card with only one unknown and it seems reasonable, treat it like any other new Anki card and answer it accordingly. For more information on handling new cards, refer to the Anki studying guide.
Skipping Cards
There are three scenarios where AnkiMorphs will automatically skip a card:
-
You have selected the
Skip cards with no unknown morphs-option the in the card-handling settings:
If the card does not have any unknown morphs, it will be skipped. -
You have selected the
Skip cards that have unknown morphs already seen today-option in the card-handling settings:
Say you have three cards:card1, card2, card3, all of which have the same unknown morph. After you have answeredcard1then the cardscard2, card3will be skipped. -
You have selected the
ignore names found in names.txt-option in preprocess settings
Let’s use the same example of three cards ,card1, card2, card3. This time they all have the same unknown morphAlexander. If you use the Mark as name feature to markAlexanderas a name oncard1, then the cardscard2, card3will be skipped.
Pre-skipping Cards
The skipping features mentioned in the section above only take effect when using Anki on desktop where the AnkiMorphs addon is activated. This can make it tricky to study new cards on mobile since there might be many cards right after each other that have the same unknown morph.
To get some of the same effects on mobile, we can instead “pre-skip” cards by selectively moving some of them farther back in the queue when we Recalc.
For more info read:
Card Handling: Shift new cards that are not the first to have the unknown morph
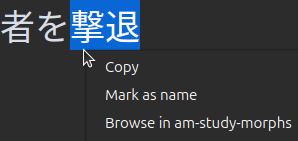
Right-Clicking Highlighted Text
AnkiMorphs adds some additional options to the Anki context menu (right-click):
-
Mark as Name:
The highlighted text will be added to the names.txt file, and the card will be skipped. -
Browse in
am-study-morphs:
This opens up the Anki Browse window with the search term:"am-study-morphs:{highlighted_text}"This can be useful for finding cards you previously studied that contained the highlighted text as an unknown morph.
For example, you might have forgotten the nuances of the word
repulse, but recall having studied it before, you can then highlightrepulse, select this option, and the browse window will open with the search term:"am-study-morphs:repulse"
Browser
AnkiMorphs adds new options in the Browse window that can be accessed either from the AnkiMorphs menu at the top or
when right-clicking cards:
-
View Morphemes:
Opens a pop-up window showing the card’s morphs -
Learn Card Now:
Raises selected cards to the top of thenew cards-queue.Note: If you use
Learn Card Nowon a card that is not in the deck you are currently studying, then it won’t show up. -
Browse Same Morphs:
Searches for all the cards that have the same morphs (inflection) as the selected card. -
Browse Same Unknown Morphs:
Searches for all the cards that have the same unknown morphs (inflection) as the selected card. -
Browse Same Unknown Morphs (Lemma):
Searches for all the cards that have the same unknown morphs (lemma) as the selected card. -
Tag As Known:
Adds theSet known and skiptag to the selected cards.
Generators
AnkiMorphs provides the following three generators:
-
Readability Report Generator
Generates a report on how well you know the text in the specified files. The results are displayed in the table at the bottom of the window (no file is created). -
Priority File Generator
Generates a.csvfile listing all morphs from the input files, sorted by frequency. -
Study Plan Generator
Generates a.csvfile by merging priority files in a specified order.
To use the generators you have to follow these three steps:
Loading Files
File Formats

These are the files that the generators are (mostly) able to read. Any files that don’t have these extensions will be ignored.
Note:
- Files must be encoded in
UTF-8. Using other encodings may lead to parsing errors or crashes.- EPUB files may be parsed slightly differently across operating systems due to system-specific quirks.
Selecting Root Folder

Any files that match your selected file formats and are in this folder or sub-folders, will be used by the generators.
Take, for example, the following folders and their files:
english_texts/
├── books/
│ └── The Wise Man's Fear/
│ ├── The Wise Man's Fear.epub
│ └── The Wise Man's Fear.txt
└── subs/
├── Game-of-Thrones/
│ └── season-1/
│ └── episode_1.srt
└── Lord_of_the_Rings/
└── The_Fellowship_of_the_Ring.vtt
If you were to select the books folder, and you checked the .txt file format, then the generator would
only use the The Wise Man's Fear.txt file.
If you were to select the folder english_texts and you checked all the file format options, then the generator would
use the files:
The Wise Man's Fear.epubThe Wise Man's Fear.txtepisode_1.srtThe_Fellowship_of_the_Ring.vtt
After Loading
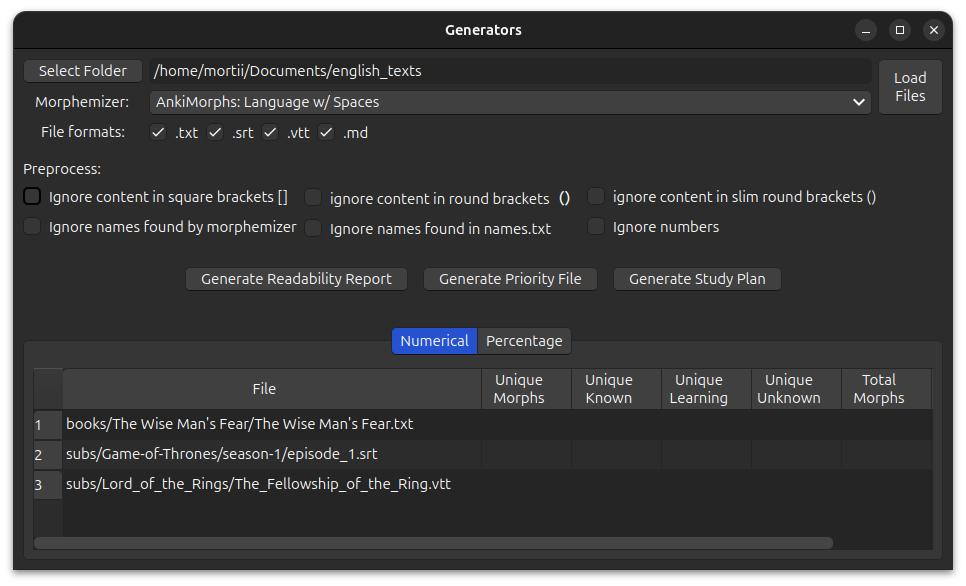
The files that will be used by the generators will be shown in the File column in the tables below, and the generator
buttons are now enabled. Next, you need to specify how the generators should process the files.
Processing Files
Morphemizer

This is the tool AnkiMorphs uses to split text into morphs.
Preprocess

These options are equivalent to those found in Preprocess settings.
Generator Output
When clicking the Generate Priority File or Generate Study Plan buttons you will be presented with these options:
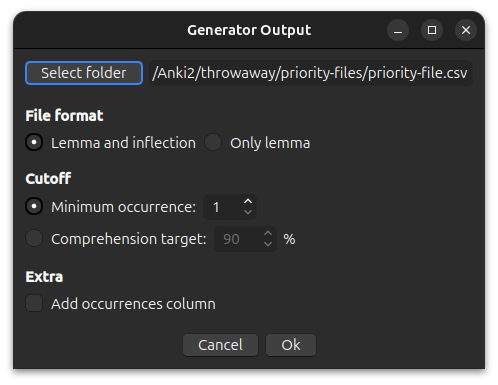
The output file is automatically set to be in the [anki profile folder]/priority-files/ folder. Any priority
files or study plans that are placed in this folder can be selected in the
note filter: morph priority settings.
You can name the file whatever you want as long as it has a .csv extension, e.g. ja-freq.csv.
File Format
Lemma and inflection: inflection priority fileOnly lemma: lemma priority file
Minimum Occurrence
Limit the morphs to only those that occur at least x many times.
Comprehension Target
Limit the morphs to only those that occur below the specified comprehension percent. Let’s look at a simple scenario where these are all the morphs:
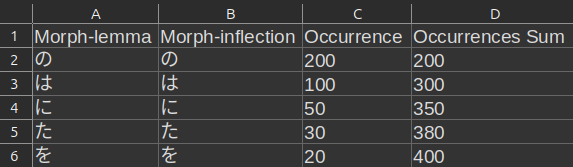
If your target is 90%, then we get:
\[ \large \text{Occurrence Sum Threshold} = 0.9 \times 400 = 360 \]
The morphs in the fifth and sixth rows would therefore not be included since they have an occurrence sum greater than 360.
Readability Report Generator
The Readability Report Generator can give you insights into how much of the text in a file you are able to read. It produces two different outputs, one with pure numerical values, and one with percentages.
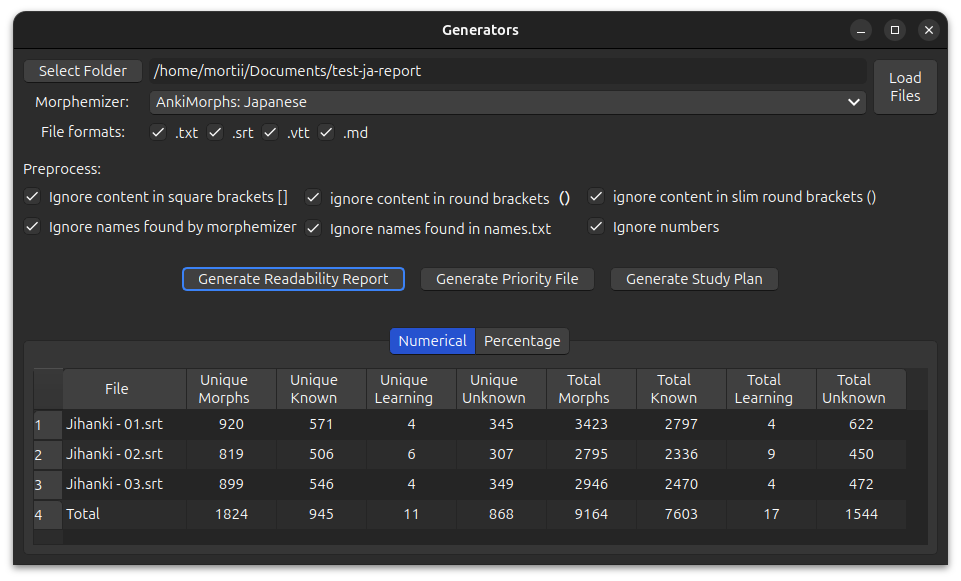
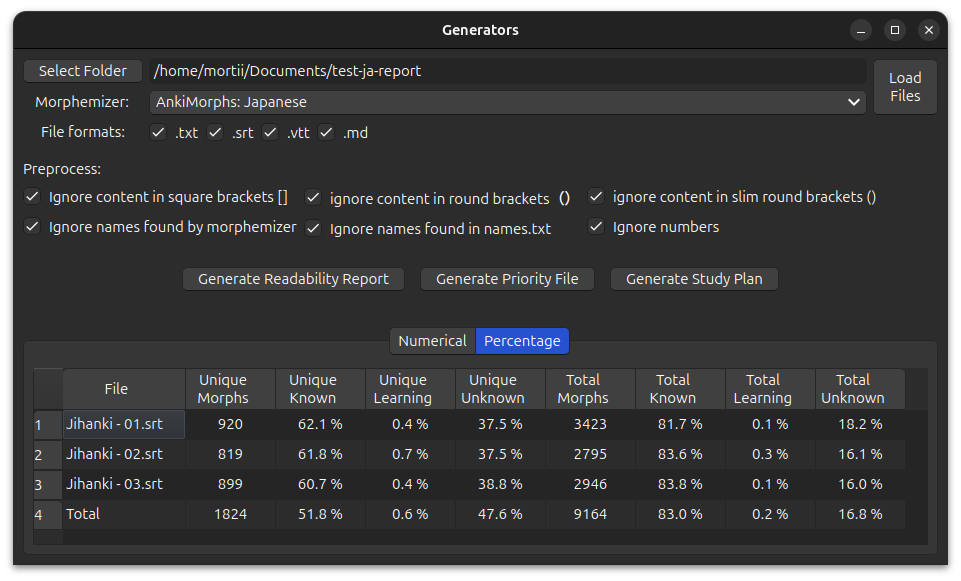
You can click on the column headers to sort the rows based on those values.
Priority File Generator
The Priority File Generator creates a priority file that is described in the prioritizing section.
Study Plan Generator
Using a study plan is convenient if you want to learn morphs from source materials in a specific sequence, e.g., TV show episodes, book series, etc.
A study plan differs from a regular priority file in the following ways:
- It is first sorted by input files, then morph frequency.
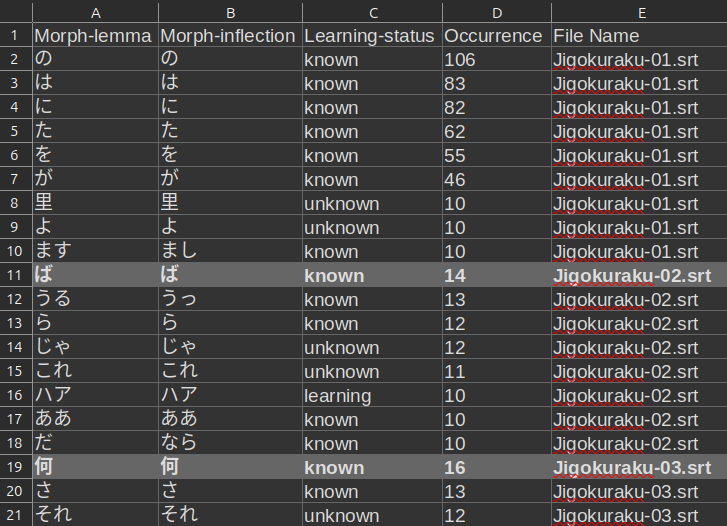
- It has extra columns:
- Learning status
- File name
The study plan generator basically does this:
- Creates a priority file for each input file
- Combines those priority files
- Removes duplicate morphs
The resulting file can be used in the note filter: morph priority settings like any other priority file.
Note: that only the data from the
Morph-Lemma, andMorph-Lnflectioncolumns are read by AnkiMorphs, so you can delete or modify the other columns if you want.
Changing The File Order
The study plan uses the same file order as that displayed in the currently opened table at the bottom of the window. This provides more flexibility than relying solely on the alphanumeric values of the file names.
If I have this table open where I sort based on the Total Known column, as I click the Generate Study Plan button :
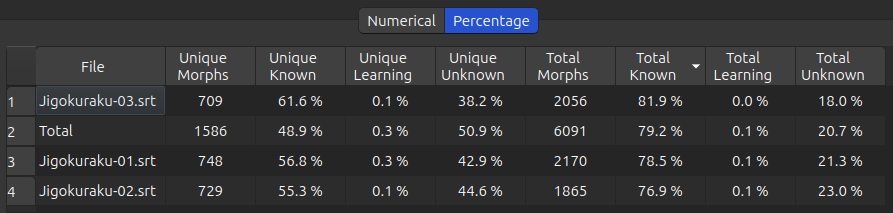
the study plan will have the files in this order:
Jigokuraku-03.srtJigokuraku-01.srtJigokuraku-02.srt
Note: the
Total“file” is artificial and won’t be included, nor is its data used in any calculations.
With this table open where I sort based on the Total Unknown column:
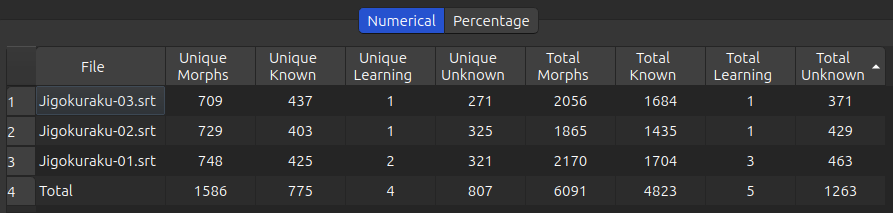
Then the order will be this:
Jigokuraku-03.srtJigokuraku-02.srtJigokuraku-01.srt
Progression
In the beginning stages of language acquisition, your working vocabulary will consist mostly of commonly used words. As your ability increases, you will recognize a richer variety of words. As you approach native-level proficiency, you will recognize almost all words – from the very common to the highly specialized.
Although AnkiMorph cannot measure true language acquisition, the Progression tool can help you understand both your learning progress and the quality of your card collection with respect to morph priority.
Setup
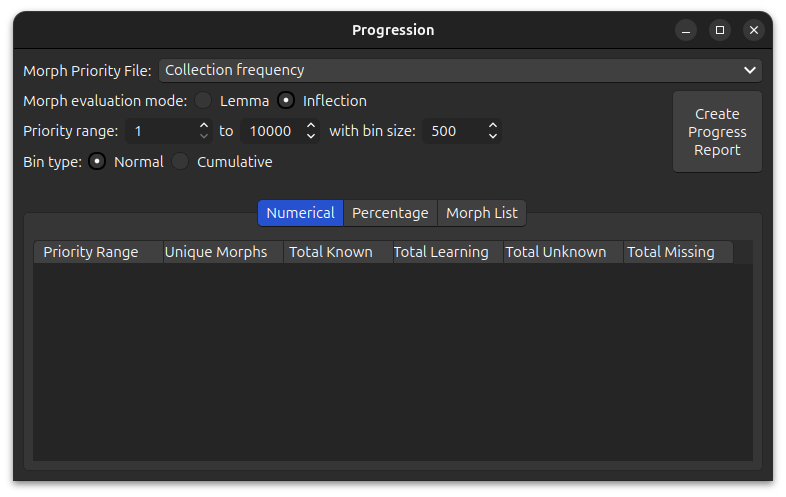
Designating Morph Priorities
Since progression is measured with respect to morph priorities, we must first decide how
morph priorities should be determined. In an identical manner to note filters, you can either use the morph
frequencies of your card collection (Collection frequency) or you can designate a custom .csv file that contains this
information. Any .csv file located in the folder anki profile folder/priority-files/ is available for selection.
Options
To gauge progression, AnkiMorphs essentially calculates a histogram. Morphs with assigned priorities are first binned
into priority ranges (e.g., priorities 1-500, 501-1000, etc.).
The user can designate the bin size:
as well as the minimum and maximum priority considered:

Note: the calculated bins may differ depending on the number of specified morph priorities.
Bins can also be cumulative:

In this mode, bin statistics will increase or decrease monotonically.
Finally, the user can specify whether morphs should be evaluated according to lemma or inflection.

This can be freely changed regardless of the mode specified in the general settings. However, if using
morph priorities from a custom .csv file, one must be sure as always that the file is compatible with the morph evaluation mode, e.g.
if you are using a lemma-only priority file, then you can only evaluate by lemma.
Results
Clicking View Progress Report will determine the current progression and populate the results.
Numerical and Percentage Tabs
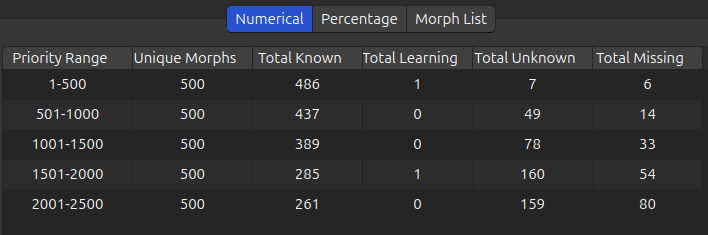
The Numerical tab reports the number of unique morphs, known morphs, learning morphs, unknown morphs, and missing morphs in each priority range (bin). Unknown morphs are present in the card collection, while missing morphs are not present in the card collection.
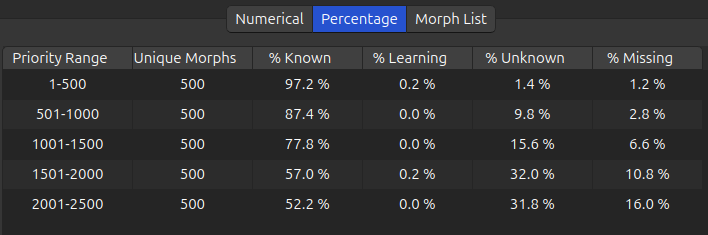
The Percentage tab reports these same statistics as percentages of unique morphs. By examining the percentage of known morphs, learning progress can be evaluated. Meanwhile, the percentage of missing morphs is an important metric of card collection quality – a deck should contain the most relevant morphs, after all.
Morph List Tab
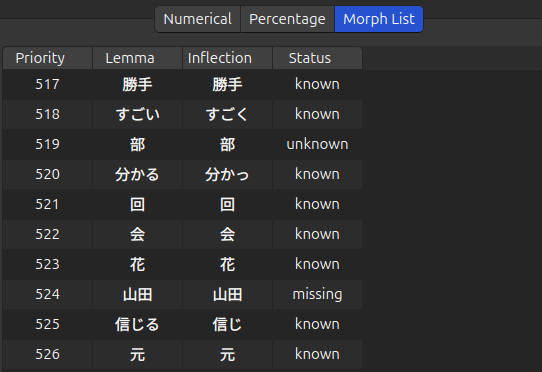
The Morph List tab provides the status of each morph with a specified priority. This information can be useful to quickly zero-in on critical morphs that are either unknown or missing from your card collection.
Reset Tags
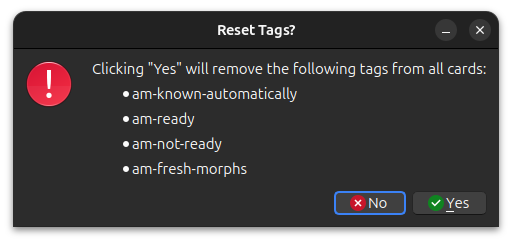
When you switch to a new morphemizer or change the morph evaluation from lemma to inflection, some tags on your cards may become incorrect or misleading and these should be removed. The tags shown in the picture above are safe to remove because they will always be reapplied during recalc.
To reset these tags, go to Tools -> AnkiMorphs -> Reset Tags
Exporting Known Morphs
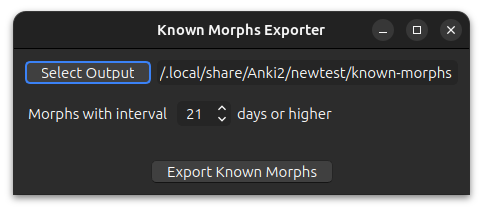
Exports all the morphs from ankimorphs.db that have the specified interval or above. Useful
for setting known morphs, which allows you to trim down your card collection.
Select Output
Select the folder you would like AnkiMorphs to save the file to.
Defaults to the [anki profile]/known-morphs folder.
Resulting File
The file name will be known_morphs-{datetime}.csv, where datetime is the time of creation, e.g.:
known_morphs-2024-01-11@18-47-19.csv
The file format will be the same as those generated by the priority file generator.
Tips & Tricks
Learning specific media
If you want to learn a specific piece of media—like a book or a movie—a targeted priority file can speed things up compared to a general one. However, ou should only really do this after you have already learned at least the most frequent 2k morphs. If you start to specialize too early you can fall into the trap of “over-fitting” your vocabulary and understanding of the language.
Reverting AnkiMorphs changes
There are a couple of ways to revert the changes AnkiMorphs has made to your card collection:
- Restore from a previous backup you made.
- If you only want to revert how AnkiMorphs sorted the cards, then you can do the following:
Browse -> Card State -> New cards -> Select all (Ctrl + A) -> Reset... -> Restore original position where possible
Using Yomitan frequency dictionaries
If you want to sort your cards using Yomitan-format frequency dictionaries, you can use this cool tool: https://github.com/NaabZer/anki-morph-frequency-prio
Known Problems
Undoing 'set known and skip'
There is a bug that occurs when you do the following:
- Open Anki
- Go to a deck and click ‘Study Now’
- Only ‘set known and skip’ cards
If you do this then those actions cannot be undone immediately. You can easily fix this by simply answering (or basically doing anything to) the next card, and you can now just undo twice and the previous ‘set known and skip’ will be undone.
This is a weird bug, but I suspect it is due to some guards Anki has about not being able to undo something until the user has made a change manually first (‘set known and skip’ only makes changes programmatically).
Redo is not supported
Redoing, i.e. undoing an undo (Ctrl+Shift+Z), is a nightmare to handle with the current Anki API. Since it is a rarely used feature, it is not worth the required time and effort to make sure it always works. Redo might work just fine, but it also might not. Use it at your own risk.
Freezing when reviewing
AnkiMorphs uses the Anki API to run in the background after you answer a card, which then displays a progress bar of how many cards have been skipped:
The Anki API has a rare bug where it sometimes gets in a deadlock and just says ‘Processing…’ forever.
When this happens you have to restart Anki.
Incorrect highlighting of ignored names
When names are ignored, either by the morphemizer or those found in the
names.txt, then the highlighting is prone to false-positives where other morphs also found in the text can mistakenly get highlighted in the names:

Readability report freezes indefinitely when input is too long
When using the
AnkiMorphs: Japanesemorphemizer, excessively long lines of text can cause the morphemizer’s buffer to overflow, causing the progress bar to freeze indefinitely. To avoid this, try splitting the long lines into shorter segments.
Anki crashing when opening AnkiMorphs settings
The
AnkiMorphs: Japanesemorphemizer doesn’t handle paths with diacritical marks very well, so paths like this:C:\Users\héroïnecan cause crashes. If you can’t change the path name that is causing the crash, try using spaCy morphemizers instead.
Changelog
View changelog on github: https://github.com/mortii/anki-morphs/releases
Frequently Asked Questions
Transitioning from MorphMan
Should I add a note-filter row for both my sentence field and my focus morph field?
No, only use the sentence field.
Should I use the same tags in AnkiMorphs that I was using with Morphman?
I recommend using the default AnkiMorphs tags. Mixing tags can get confusing.
Should I export all of studied and in progress words into a CSV spreadsheet?
AnkiMorphs determines which morphs are known in the same way MorphMan does it: by how long the learning intervals of the cards are. The Known Morphs Exporter is more of a tool for trimming your card collection, it’s not a requirement for transitioning from MorphMan.
If you want to retain the morphs on cards that you have tagged as known with MorphMan, then I recommend bulk tagging
those
cards with am-known-manually:
- Open
Browse - Select the MorphMan known tag in the sidebar
- Select all those cards
- Go to
Notesin the topbar and click onAdd Tags(or use Ctrl+Shift+A) - Enter the tag
am-known-manually
That approach could be overkill though. I wouldn’t worry too much about losing known morphs from the cards you tagged as
known with MorphMan, you can usually get them back quickly by using K when you encounter them when using AnkiMorphs.
Should I manually delete the words in the focus morph field of my cards so that AnkiMorphs can cleanly reparse everything?
AnkiMorphs does not reuse the MorphMan focus morph field, so it makes no difference.
Setup
Linux
-
Installing python 3.13:
The latest version of Anki uses python 3.13, and we need our dev environment to match the prod environment in order to catch any bugs that are exclusive to those particular set of dependencies.When this command succeeds:
$ python3.13 --version Python 3.13.[x]then you are ready move on to the next step.
-
Setting up the dev environment:
We want to use a virtual environment for a few reasons: we don’t want to install the project’s dependencies on the global environment (your pc) because you might end up with package conflicts or accidentally downgrading packages, etc; a virtual environment also makes sure the dependencies are consistent for all developers.
python3.13 -m pip install --upgrade pip virtualenv python3.13 -m virtualenv venv source venv/bin/activate # <--- this activates the virtual environment python -m pip install --upgrade pip python -m pip install -r requirements.txt pre-commit install # use this command if you want/need spaCy models . setup-spacy-models.sh # use this command if you want/need CAMeL databases # note: only works on linux and macOS . setup-camel-packages.shAlso install
Xvfbon your system, e.g.:sudo apt-get install xvfb, this prevents windows popping up whenpre-commitrunspytest.Remember to activate the virtual environment any time before you start working on the project, some IDEs do this automatically.
-
Set the project python interpreter to be
anki-morphs/venv/bin/pythonto get your IDE to recognize the packages installed above. -
Create a soft symbolic link from the cloned repo to the anki add-ons folder so anki starts using the dev AnkiMorphs:
ln -s ~/path/to/cloned/repo/anki-morphs/ankimorphs ~/.local/share/Anki2/addons21/ankimorphs -
Using pre-commit:
Pre-commit runs some commands (pylint, pytest, etc.) on the code before you commit to make sure the code is in good condition. Pre-commit is configured in
.pre-commit-config.yamland some of the commands have additional configurations inpyproject.toml.You can run it manually with the command:
pre-commit run -aIf you want to make an intermediate commit without caring about pre-commit running successfully you can use the
--no-verifyflag, e.g.git commit -am "fixed abc" --no-verifyPre-commit can be annoying to use in the same way that it can be annoying to follow traffic-laws–sure it might slow you down right now, but it is much better in the long-run when everybody does it. Pre-commit can help you in three ways:
- Automatically fix code for you
- Catch bugs earlier
- Make code more understandable
Once you get used to the pre-commit flow it no longer slows you down, and there are only upsides to using it.
Pre-commit fails in two ways:
-
Automatically fixed
When a pre-commit hook changes a file (fixing it) then you simply have to re-stage the file and re-run the commit. E.g:$ vim recalc_main.py $ git commit -am "made changes" isort (python)..........Failed - hook id: isort - files were modified by this hook Fixing /home/{...}/recalc_main.py $ git commit -am "made changes" [main c0bd018] made changes 1 file changed, 56 insertions(+) -
Has to be manually fixed
The majority of the hooks provide warnings that have to be handled manually. Most of the time the required fixes provide significant improvements to the code, and you might learn something new and become a better programmer in the process. Sometimes the suggested errors are false-positive, or the suggested fix is actually problematic in some way. When this happens then ignoring it is fine, e.g:from aqt.qt import QMessageBox # pylint:disable=no-name-in-module
Optional: if you use gitkraken you have to adjust the pre-commit script (
anki-morphs/.git/hooks/pre-commit) to activate the virtual environment first:#!/usr/bin/env bash # File generated by pre-commit: https://pre-commit.com # ID: 138fd403232d2ddd5efb44317e38bf03 # start templated ANKIMORPH_DIR=/home/mortii/git/anki-morphs/ # <--- ADD THIS LINE! INSTALL_PYTHON=/home/mortii/git/anki-morphs/venv/bin/python3 ARGS=(hook-impl --config=.pre-commit-config.yaml --hook-type=pre-commit) # end templated HERE="$(cd "$(dirname "$0")" && pwd)" ARGS+=(--hook-dir "$HERE" -- "$@") if [ -x "$INSTALL_PYTHON" ]; then cd $ANKIMORPH_DIR && source venv/bin/activate # <--- ADD THIS LINE! exec "$INSTALL_PYTHON" -mpre_commit "${ARGS[@]}" elif command -v pre-commit > /dev/null; then exec pre-commit "${ARGS[@]}" else echo '`pre-commit` not found. Did you forget to activate your virtualenv?' 1>&2 exit 1 fi
Debugging
Debugging tools for Anki add-ons are unfortunately fairly limited. The simplest approach is to use print statements in the code which can then be seen in a terminal that spawned the Anki instance. Here is the guide for doing that: https://addon-docs.ankiweb.net/console-output.html#showing-the-console
Redirecting the terminal output to a file can be very useful. Here is a linux example:
anki > anki_output.txt
There is also a dedicated test function in the AnkiMorphs code that allows for faster/easier testing, you can find it here: __init__.py: test_function
Docs
This website was made using mdBook and is hosted on Github Pages.
mdBook
The official mdBook guide is pretty good and walks you through the entire setup process and how to use it.
First install rust to get the cargo package manager:
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh
install mdbook:
cargo install mdbook
Launch mdbook from the AnkiMorphs directory with the command:
mdbook serve docs/ --open
MathJax
MathJax is used to display the latex equations.
Github Pages
To make github automatically deploy the generated book to github pages do the following:
- Activate Github Actions:
Github repo settings → Code and automation → Pages → Build and deployment → Github Actions - Make any necessary adjustments to branch names or paths in:
anki-morphs/.github/workflows/deploy.yml
Project sites will be available at:
http(s)://<username>.github.io/<repository>
Styling
For additional spacing between bullet points, you have to add a space between at least one of the points, e.g.:
* **a**:
a
* **b**:
b
* **c**:
c
Qt Designer
Creating dialogs with Qt Designer is often much easier than building them by hand. Installing Qt Designer via pip can
cause dependency conflicts, so it’s recommended to install the standalone version instead:
sudo apt install qt6-tools-dev-tools
Start Qt Designer with the command:
/usr/lib/qt6/bin/designer
Convert ui file to python:
pyuic6 -o ankimorphs/ui/settings_dialog_ui.py ankimorphs/ui/settings_dialog.ui
pyuic6 -o ankimorphs/ui/tag_selection_dialog_ui.py ankimorphs/ui/tag_selection_dialog.ui
pyuic6 -o ankimorphs/ui/generators_window_ui.py ankimorphs/ui/generators_window.ui
pyuic6 -o ankimorphs/ui/known_morphs_exporter_dialog_ui.py ankimorphs/ui/known_morphs_exporter_dialog.ui
pyuic6 -o ankimorphs/ui/view_morphs_dialog_ui.py ankimorphs/ui/view_morphs_dialog.ui
pyuic6 -o ankimorphs/ui/generator_output_dialog_ui.py ankimorphs/ui/generator_output_dialog.ui
pyuic6 -o ankimorphs/ui/progression_window_ui.py ankimorphs/ui/progression_window.ui
pyuic6 -o ankimorphs/ui/spacy_manager_dialog_ui.py ankimorphs/ui/spacy_manager_dialog.ui
Useful guides:
- https://realpython.com/qt-designer-python/
- https://www.pythontutorial.net/pyqt/qt-designer/
Tests
The testing framework is Pytest with these plugins:
- pytest-qt: allows for writing tests for PyQt5, PyQt6, PySide2 and PySide6 applications.
- pytest-xvfb: allows tests to be run without windows popping up during GUI tests or on systems without a display (like a CI).
- pytest-expect: stores test expectations by saving the set of failing tests, allowing them to be marked as xfail when running them in the future.
- pytest-sugar: showing failures and errors instantly, adding a progress bar, and making the output look better.
- pytest-randomly: randomly order tests and control random seed.
Some default options are set in the pyproject.toml file under the [tool.pytest.ini_options] section.
Running tests
From the project root folder you can run tests with the command pytest, and it will automatically gather and run all
the tests found in the tests directory.
You can restrict the tests to a specific file by appending the path(s) to the command, e.g:
pytest test/tests/recalc_test.py test/tests/review_test.py
You can also add “tags” to specific tests and run all the tests that have those tags. This is done by adding the
decorator @pytest.mark.{tag}, e.g. @pytest.mark.external_morphemizers, and you can then run those tests with the
command:
pytest -m external_morphemizers
Note: the “tag” also has to be added to the “markers” list in
pyproject.tomlbecause we run tests with the--strict-markersargument.
You can specify how many fails the tests should abort after with the --maxfail argument, e.g:
pytest --maxfail=10
The pytest-randomly plugin runs the tests in a random order based on a seed. You can specify the seed:
pytest --randomly-seed=84903385
You can also rerun the last used seed:
pytest --randomly-seed=last
Test coverage
Run: pytest --cov=ankimorphs --cov-report html and click on index.html in htmlcov/
Card collections
Note:
- all of these collections have all the extra fields selected
- the extra fields contain inflections unless stated otherwise
- morphs are evaluated based on inflections unless stated otherwise
- morphs priority is ‘Collection Frequency’ unless stated otherwise
Current card collections (test/data/card_collections):
lemma_evaluation_lemma_extra_fields_collection.anki2- contains two “known” cards (“the”, “man”), and then 9 cards with 4 lemmas and 9 inflections. this is used for testing if the inflections are given the scores of their respective lemmas and the inflections are skipped on review.
- the extra fields contain lemmas
- morphs are evaluated based on lemma
- morphemizer: ‘spaCy: en_core_web_sm’
some_studied_lemmas_collection.anki2- duplicate of
lemma_evaluation_lemma_extra_fields_collection.anki2, but one card for each lemma has been studied, so the other cards that have those lemmas should contain no unknowns. - the extra fields contain lemmas
- morphs are evaluated based on lemma
- morphemizer: ‘spaCy: en_core_web_sm’
- duplicate of
big_japanese_collection.anki2- monolithic card collection (https://github.com/mortii/anki-decks)
- morphemizer: ‘Ankimorphs Japanese’
ignore_names_txt_collection.anki2- Contains one card that has two names, one of which is found in names.txt
- morphemizer: ‘AnkiMorphs: Language w/ Spaces’
known-morphs-collection.anki2- contains one card with 7 morphs, 6 of which are found in the ‘known-morphs-valid’ directory
- morphemizer: ‘AnkiMorphs: Language w/ Spaces’
offset_new_cards_inflection_collection.anki2- Contains two cards, both with “hello”.
recalc_offset_new_cardsconfig option enabled- morphemizer: ‘AnkiMorphs: Language w/ Spaces’
offset_new_cards_lemma_collection.anki2- duplicate of
lemma_evaluation_lemma_extra_fields_collection.anki2, but has uses therecalc_offset_new_cardsconfig option enabled - the extra fields contain lemmas
- morphs are evaluated based on lemma
- morphemizer: ‘spaCy: en_core_web_sm’
- duplicate of
some_studied_japanese_collection.anki2- contains three cards:
- one that has the tag ‘am-known-manually’
- one with a learning interval of 1 day
- one with a learning interval of 30+ days
- morphemizer: ‘Ankimorphs Japanese’
- contains three cards:
max_morph_priority_collection.anki2- contains two cards, and uses the priority file
ja_core_news_sm_freq_inflection_min_occurrence.csv. One card has a morph that is found in the priority file, the other card does not, which should give it a max morph priority value. - morphemizer: ‘spaCy: ja_core_news_sm’
- contains two cards, and uses the priority file
card_handling_collection.anki2- contains 6 cards:
- 3 known, not new cards
- 1 fresh, not new card
- 1 with only known or fresh morphs, new card
- 1 with known, fresh, and one unknown morph, new card
- creating an evergreen collection that has fresh morphs is surprisingly difficult, because the due date of the card actually depends on the timestamp of card creation. To make this problem go away you can set the date of your system back a couple of months and then create the cards.
- contains 6 cards:
suspend_all_morphs_known.anki2- the base of this collection is
card_handling_collection.anki2, that has been recalced with the configconfig_suspend_morphs_known
- the base of this collection is
suspend_morphs_known_or_fresh.anki2- the base of this collection is
card_handling_collection.anki2, that has been recalced with the configconfig_suspend_morphs_known_or_fresh
- the base of this collection is
move_to_end_morphs_known.anki2- the base of this collection is
card_handling_collection.anki2, that has been recalced with the configconfig_move_to_end_morphs_known
- the base of this collection is
move_to_end_morphs_known_or_fresh.anki2- the base of this collection is
card_handling_collection.anki2, that has been recalced with the configconfig_move_to_end_morphs_known_or_fresh
- the base of this collection is
card_stability_collection.anki2- contains ~100 cards from a real and mature collection, same filters as
big_japanese_collection,
- contains ~100 cards from a real and mature collection, same filters as
card_interval_collection.ank2- same as
card_stability_collection.anki2but recalced withoutUSE_STABILITY_FOR_KNOWN_THRESHOLD
- same as
Engineering and adding collections
- create a new anki profile
- (optional) create a new deck
- (optional) create a new note type
- add cards and change the ankimorphs settings to fit the use case
- recalc
- exit anki/close the profile
- extract the
collection.anki2file from the profile directory and rename it to something relevant to the use case and place the renamed collection file intest/data/card_collections - repeat this process for the
ankimorphs.dbif the tests require it, and move it totest/data/am_dbs - create a new fake config in
test/fake_configs.pyand make any necessary adjustments to have it match the settings used when you previously ran recalc.
Investigating collections
Basically reverse the steps in the section above, i.e:
- extract the collection file you are interested in
- rename the collection to
collection.anki2 - place the file in the profile folder of a new anki profile
- open the anki profile and the cards should be available for viewing
Priority files
The priority files found in correct_outputs are generated with the following settings:
- all the file formats selected
- none of the preprocess options selected
- occurrences column is always added
- when comprehension is selected the target is always
90% - when minimum occurrence is used the target is always
1
Databases
ankimorphs.db
This is an sqlite database with three tables:
'Cards'
'Card_Morph_Map'
'Morphs'
A card can have many morphs, morphs can be on many cards, so we need a many-to-many db structure:
Cards -> Card_Morph_Map <- Morphs
Card table
card_id INTEGER PRIMARY KEY ASC,
note_id INTEGER,
note_type_id INTEGER,
card_type INTEGER,
tags TEXT
Card_Morph_Map table
card_id INTEGER,
morph_lemma TEXT,
morph_inflection TEXT,
FOREIGN KEY(card_id) REFERENCES card(id),
FOREIGN KEY(morph_lemma, morph_inflection) REFERENCES morph(lemma, inflection)
Morph table
lemma TEXT,
inflection TEXT,
highest_learning_interval INTEGER,
PRIMARY KEY (lemma, inflection)
To make sure the morphs are unique, we make the primary key the lemma AND inflection, since inflections can be identical even if they are derived from two different bases, eg:
Inflection : Lemma
ある : 有る
ある : 或る
Using an int as a primary key is preferable over text objects, but hashing the lemma and inflection would lead to a high likelihood of collisions because of the following:
# sqlite integers are max 2^(63)-1 = 9,223,372,036,854,775,807
# The chance of hash collision is 50% when sqrt(2^(n/2)) where n is bits of the hash
# With 64 bits the prob of collision becomes sqrt(2^(64/2)) = 65,536
So if we have over 65,536 morphs we would likely experience bugs that are basically impossible to trace.
Anki dbs
table_info = mw.col.db.execute("PRAGMA table_info('decks');")
print(f"table_info: {result}")
Anki collection db tables:
[['col'],
['notes'],
['cards'],
['revlog'],
['deck_config'],
['config'],
['fields'],
['templates'],
['notetypes'],
['decks'],
['sqlite_stat1'],
['sqlite_stat4'],
['tags'],
['graves']]
notes table:
[[0, 'id', 'INTEGER', 0, None, 1],
[1, 'guid', 'TEXT', 1, None, 0],
[2, 'mid', 'INTEGER', 1, None, 0],
[3, 'mod', 'INTEGER', 1, None, 0],
[4, 'usn', 'INTEGER', 1, None, 0],
[5, 'tags', 'TEXT', 1, None, 0],
[6, 'flds', 'TEXT', 1, None, 0],
[7, 'sfld', 'INTEGER', 1, None, 0],
[8, 'csum', 'INTEGER', 1, None, 0],
[9, 'flags', 'INTEGER', 1, None, 0],
[10, 'data', 'TEXT', 1, None, 0]]
notetypes table:
[[0, 'id', 'INTEGER', 1, None, 1],
[1, 'name', 'TEXT', 1, None, 0],
[2, 'mtime_secs', 'INTEGER', 1, None, 0],
[3, 'usn', 'INTEGER', 1, None, 0],
[4, 'config', 'BLOB', 1, None, 0]]
cards table:
'id' ID_FIELD_NUMBER: builtins.int
'nid' NOTE_ID_FIELD_NUMBER: builtins.int
'did' DECK_ID_FIELD_NUMBER: builtins.int
'ord' TEMPLATE_IDX_FIELD_NUMBER: builtins.int
'mod' MTIME_SECS_FIELD_NUMBER: builtins.int # when card was modified
'usn' USN_FIELD_NUMBER: builtins.int
'type' CTYPE_FIELD_NUMBER: builtins.int
'queue' QUEUE_FIELD_NUMBER: builtins.int
'due' DUE_FIELD_NUMBER: builtins.int
'ivl' INTERVAL_FIELD_NUMBER: builtins.int
'factor' EASE_FACTOR_FIELD_NUMBER: builtins.int
'reps' REPS_FIELD_NUMBER: builtins.int
'lapses' LAPSES_FIELD_NUMBER: builtins.int
'left' REMAINING_STEPS_FIELD_NUMBER: builtins.int
'odue' ORIGINAL_DUE_FIELD_NUMBER: builtins.int
'odid' ORIGINAL_DECK_ID_FIELD_NUMBER: builtins.int
'flags' FLAGS_FIELD_NUMBER: builtins.int
'data' custum_data builtins.str
‘type’ is the learning stage type:
CardType = NewType("CardType", int)
CARD_TYPE_NEW = CardType(0)
CARD_TYPE_LRN = CardType(1)
CARD_TYPE_REV = CardType(2)
CARD_TYPE_RELEARNING = CardType(3)
‘queue’ types:
CardQueue = NewType("CardQueue", int)
QUEUE_TYPE_MANUALLY_BURIED = CardQueue(-3)
QUEUE_TYPE_SIBLING_BURIED = CardQueue(-2)
QUEUE_TYPE_SUSPENDED = CardQueue(-1)
QUEUE_TYPE_NEW = CardQueue(0)
QUEUE_TYPE_LRN = CardQueue(1)
QUEUE_TYPE_REV = CardQueue(2)
QUEUE_TYPE_DAY_LEARN_RELEARN = CardQueue(3)
QUEUE_TYPE_PREVIEW = CardQueue(4)
Contributors
A huge thank you to all the people who have made this project possible! Contributors are listed in (hopefully) chronological order. If you have contributed, but you are not on the list, create an issue on GitHub where you let me know, and I’ll add you ;)
Code contribution
mortii, Vilhelm-Ian, xofm31, Jcuhfehl, schiozzone, Tartee, wolearyc, mdraves91, hans, RobHelgeson, JSchoreels, Rct567, circle3451.
Docs contribution
Matt Vs Japan, mortii, Vilhelm-Ian, cocowash, xuiqzy, xofm31, zeroeightysix, wolearyc, Celebes, RobHelgeson, nathanielvirgo, BenjaminBrandtner, RezeScarlet, circle3451.
Bugs reports, feature requests, or other helpful guidance
Vilhelm-Ian, CodeWithMa, ashprice, aleksejrs, HQYang1979, soliviantar, buster-blue, rymiel, BorisNA, wrinkledeth, cocowash, asayake-b5, quietmansoath, MichaelPetre, xofm31, knoebelja, xuiqzy, Jcuhfehl, fuquasteve, pallas42, syfgk, jahnke, jsteel44, iwouldrathernotusegithub, tanhoaian01, drkthomp, Kirchheim, zeroeightysix, Gardengul, wolearyc, Pedrubik2000, RyanMcEntire, BobvanSchendel, khanguyenwk, buqamura, Rct567, rwmpelstilzchen, bie-zheng, IncontinentCell, mdraves91, dae, AtilioA, BenjaminBrandtner, JSchoreels, weirdalsuperfan, NaabZer, JCFDGG, ryuk4real, QinSisuo, Clahane, Thiago-Morais.
MorphMan (v5.0-qt6-alpha.1)
Joseph Re, Jeremy Neiman, Chang Spivey, Patrice Peterson, Greg Price, kaegi, Landon Epps, InfiniteRain, David Lõssenko, imd, Shan Rauf, derpue, ianki, ym555, Zachery Gyurkovitz, David Gaya, Sara Aimée Smiseth, Yiufung Cheong, Daniel M German, sb7297, RisingOrange, Joe Strong, Jeffrey Ying, rameauv.